How AI Can Improve Scientific Decision-Making in Drug Discovery Programs
The organizational challenge is to make the reasoning process repeatable enough that teams can benefit from that level of judgment even when the expert is not in every room.
.png)
Why iteration quality matters more than search speed
Most conversations about AI in drug discovery still center on speed. Faster search, faster summaries, faster document drafting. Those gains are important, but they describe the surface of the problem rather than its core.
Drug discovery does not create value by producing answers quickly. It creates value through iteration, progressively reducing uncertainty about biology, patients, mechanisms, modalities, biomarkers, and development paths.
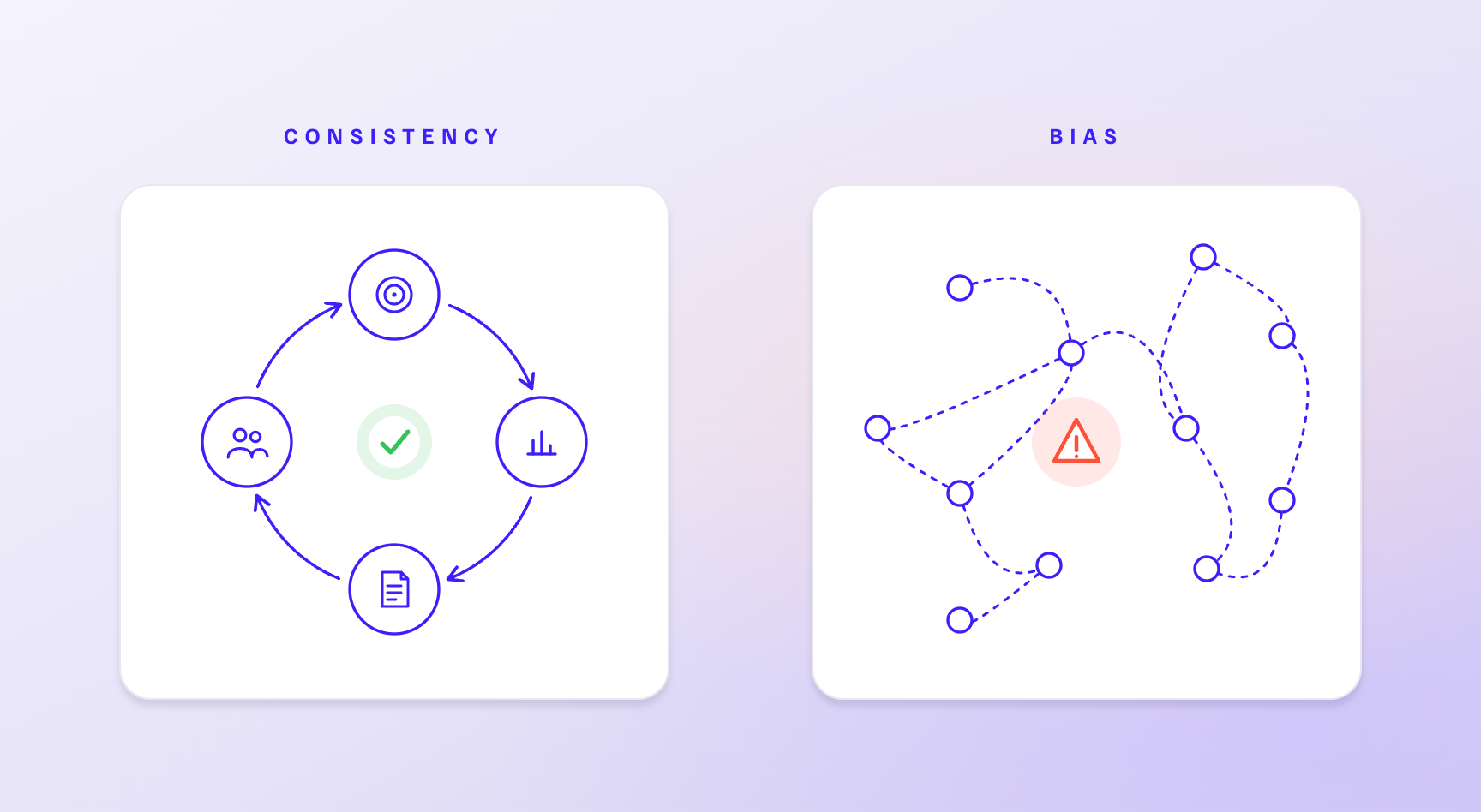
First answers are rarely right, so the quality of a discovery organization depends on how well it learns from each cycle of hypothesis, evidence, experiment, result, interpretation, and decision.The part that gets missed is that iteration only compounds into learning when the decision logic stays consistent across cycles. Without that consistency, iteration is just motion.
Iteration only compounds into learning when the decision logic stays consistent across cycles. Without that consistency, iteration is just motion.
With it, iteration becomes institutional learning. In drug discovery this makes consistency a scientific capability, because it determines whether a team can compare one experiment with the next, whether negative data becomes useful rather than inconvenient, whether outliers get examined rather than discarded, and whether the organization carries forward the reasoning behind each decision.
A program usually starts with an incomplete and partly wrong model of disease biology. The team may have a plausible target, a suggestive genetic association, a disease pathway, an assay result, or a clinical precedent.
The organization has to learn whether the biology is causal, which patients are relevant, which modality can reach the right tissue and pathway, what biomarker can read out the intervention, which indication is most tractable, and what safety and efficacy trade-offs are acceptable.
A senior leader I spoke with recently described a path that illustrates the point: A program can begin by learning from a first-generation kinase inhibitor, evolve through understanding where that biology is clinically meaningful, extend toward a new modality against the same pathway, incorporate omics panels to refine the disease model, and eventually build a rationale for combination therapy in selected patient settings.
The value is not the isolated insight that one pathway matters. The value is the cumulative reasoning chain across mechanism, patient biology, translational evidence, clinical feasibility, and portfolio judgment.
The organizational challenge is to make the reasoning process repeatable enough that teams can benefit from that level of judgment even when the expert is not in every room.
What keeps iteration from compounding into learning
The core failure mode in discovery is that successive decisions are often made with different implicit standards. Evidence thresholds shift depending on who owns the idea, which lab produced the data, how much has already been invested, or how attractive the mechanism feels.
When that happens, an organization can run many experiments without learning in a disciplined way.
For iteration to compound, several things have to stay consistent.
- Hypotheses must be stated clearly enough that they can be tested.
- Evidence must be assembled with a stable standard for relevance, quality, and contradiction.
- Experiments must be designed to reduce a specific uncertainty rather than to generate more data.
- Results must be measurable and interpretable, so the team knows whether the hypothesis was strengthened, weakened, falsified, or simply not tested well.
- Decisions must be tied to criteria set before the result is known, not retrofitted afterward.
- And the rationale must be preserved, so future teams understand not only what was decided but why.
Scientific progress often requires creativity, opportunism, and the willingness to reinterpret data. Creativity is most valuable when it operates inside a disciplined learning loop. The goal is to standardize the quality of reasoning that produces conclusions.
How bias breaks the discovery iteration loop
This is where bias becomes central, and the familiar claim that bias is bad is too generic to be useful. The sharper point is that bias breaks consistency across iterations. It causes the same kind of evidence to be treated differently depending on whether it supports or threatens the current belief.
It causes teams to protect favored mechanisms, favored hypotheses, favored labs, and favored narratives. It makes outlier data easy to dismiss when inconvenient and easy to amplify when it fits what the team already wants to believe.
In discovery, this is not a soft behavioral issue, because it directly damages scientific learning. If a team overweights data from a preferred lab, it is no longer applying a consistent evidence standard. If a contradictory omics signal is ignored because the pathway has historically been considered irrelevant, the organization may miss exactly the outlier that should have changed the model.
Controlling bias, therefore, belongs inside the operating system of discovery. A bias-resistant process forces the team to ask what they would conclude from this evidence if it supported a hypothesis they did not like, what contradictory evidence exists, and which decision criteria were specified before the result.
Where AI fits into the scientific reasoning process
AI can help here because the problem is too large and too longitudinal for human process discipline alone. In a complex program, relevant evidence sits across external literature, internal reports, omics datasets, protocols, prior decision memos, safety reviews, clinical documents, competitive intelligence, and the tacit memory of experts.
Human teams reason well, but they cannot reliably hold complete context across all of those sources and across years of program evolution.
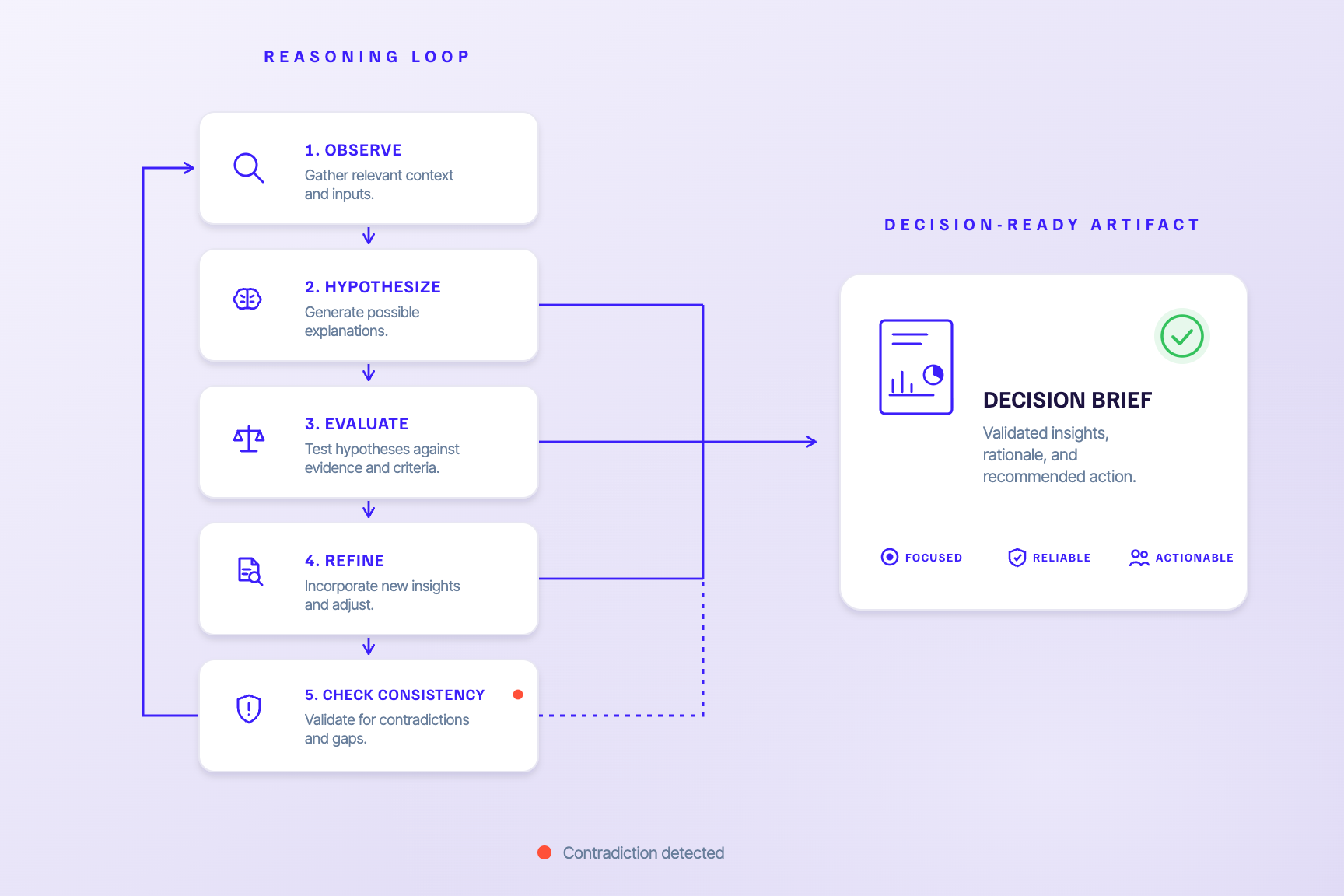
The most valuable role for AI is not to replace scientific judgment. It is to discipline and augment the process around judgment. As I have argued in how AI can move from retrieval to reasoning, a useful system turns discussion into structured hypotheses, retrieves evidence with provenance including the evidence that contradicts the hypothesis, and makes the absence of evidence explicit.
It can compare a proposed experiment against the uncertainty it is meant to reduce, preserve the original hypothesis and decision criteria, and flag when interpretation has drifted from the logic the team set out at the start.
This is fundamentally an agentic problem rather than a single search task, which is why the shift from copilots to agentic workflows matters so much for R&D.
A useful agentic system maintains the continuity of the reasoning loop and asks the next discipline-preserving question at the right moment: what hypothesis are we testing, what evidence contradicts it, what result would change our decision, what prior decision does this resemble, and what have we assumed without proving.
Getting there depends on turning workflows into executable systems with explicit steps, predictable artifacts, and inspectable stop conditions, and on holding outputs to a clear standard for what makes an agentic workflow decision-ready.
Individual scientists can use it to sharpen hypotheses and retrieve evidence, program teams can use it to compare competing hypotheses against a common evidence standard, and leadership can use it to review whether decisions are being made with consistent logic across programs and therapeutic areas.
Why AI belongs inside reasoning infrastructure, not search
The most important implication is that AI in drug discovery should not be framed only as faster search, summarization, or document generation. Those capabilities matter, but they do not address the highest-order problem.
Discovery organizations have to make repeated, uncertain, high-consequence decisions under incomplete information, and the differentiator is whether those decisions get progressively better through disciplined iteration.
A system that improves consistency, reduces bias, preserves decision memory, and requires explicit hypotheses can change the rate at which an R&D organization learns.
It can help scarce senior judgment scale across teams, make negative data more valuable, reduce the chance that outlier signals are missed, and keep the organization from drifting between hypotheses without noticing that the underlying decision logic has changed. It positions AI as infrastructure for scientific reasoning itself: not the source of judgment, but the system that helps teams apply judgment more consistently across time.
See how Causaly Scientific Workflows make the discovery reasoning loop explicit and evidence-backed. Visit the platform.
Further reading

.png)
.png)


.png)

.png)
.png)

Get started with Causaly
Ready to transform the way your R&D teams discover and deliver? Take the first step - see Causaly for yourself.
Request a demo