When Does Agentic AI Know It Has Searched Enough Resources?
It is tempting to read a long citation list as a sign of thoroughness. Twelve papers drawn from the same subfield show depth in one corner of the question and nothing elsewhere, and several of them may describe the same finding in slightly different words.

An agentic AI system can write a fluent, well-cited response and still have read only the most visible parts of the literature, missing the genetics paper or the early clinical signal that would change a program decision. What separates a research tool from a confident summarizer is whether it knows when it has searched enough.
There are two ways an AI system can answer a scientific question. It can rely on the knowledge baked into the model during training, or it can retrieve evidence first and reason over what it finds. For life sciences, the first option does not hold up. An answer has to be traceable to primary literature, with an evidence base that grows every day well beyond any training cutoff.
A model working from its own memory cannot show the papers behind a claim or be verified against them. Retrieval is what makes a scientific answer accountable. Even then, the amount a system retrieves varies widely, and two systems running the same query can come back with very different evidence. Did it find the right evidence? How much of it did it find?
Causaly can measure this, and the difference in what systems retrieve is larger than the difference in how well they write.
A confident answer is not a complete one
Consider a scientist asking for the most promising therapeutic targets and biomarkers for systemic lupus erythematosus and lupus nephritis. An AI system retrieves papers, selects the most relevant, and writes an answer with about a dozen citations. It names the targets you would expect — BAFF, type I interferon, B-cell depletion, complement — and lists the familiar biomarkers: anti-dsDNA, complement levels, proteinuria. The targets are real, the papers are real, and nothing in the answer is wrong.
The evidence that answers this question well is spread across at least six distinct areas: human genetics and causal inference, single-cell and renal tissue biology, urine proteomics, treatment-response biomarkers, the distinction between systemic disease and kidney-specific disease, and druggability.
A search built on common terms leans toward review articles and the best-known therapeutic classes, so it recovers the canonical story and little else. It misses the urine proteomics and renal single-cell work pointing to IL-16 as a non-invasive marker and possible target in lupus nephritis, the single-cell and immune-repertoire studies surfacing CD74, the finding that baseline IgA2 anti-dsDNA predicts belimumab response after rituximab, and the causal genetic analyses nominating targets such as BLK and IL12A beyond the usual mechanisms.
Those dozen citations might cover two of the six areas and leave the other four blank. The answer reads as complete even though it covers only part of the relevant science.
Why citation count is not a coverage measure
It is tempting to read a long citation list as a sign of thoroughness. Twelve papers drawn from the same subfield show depth in one corner of the question and nothing elsewhere, and several of them may describe the same finding in slightly different words. What counts is how many distinct evidence dimensions those papers cover. Twenty genetics papers and nothing on tissue biology is a biased answer, however long the reference list runs.
Most AI retrieval systems have no mechanism to flag this. The system matches the query, ranks the hits, takes the top few, and stops. Nothing in that loop asks which kinds of evidence are still missing, or whether the search should continue before the answer is written.
Search as evidence sampling
The clearest way to think about this is sampling. The evidence relevant to a hard biomedical question is spread across a large space. A few keyword queries touch a small part of that space, so the answer gets built from whatever is easy to reach. Retrieval that broadens and reranks covers far more of the relevant ground before anything is written.
The figure below shows the contrast. On the left, a handful of queries sample a thin slice of the evidence, and the answer inherits the gaps. On the right, retrieval and ranking reach most of the relevant areas, and the answer rests on a fuller base.
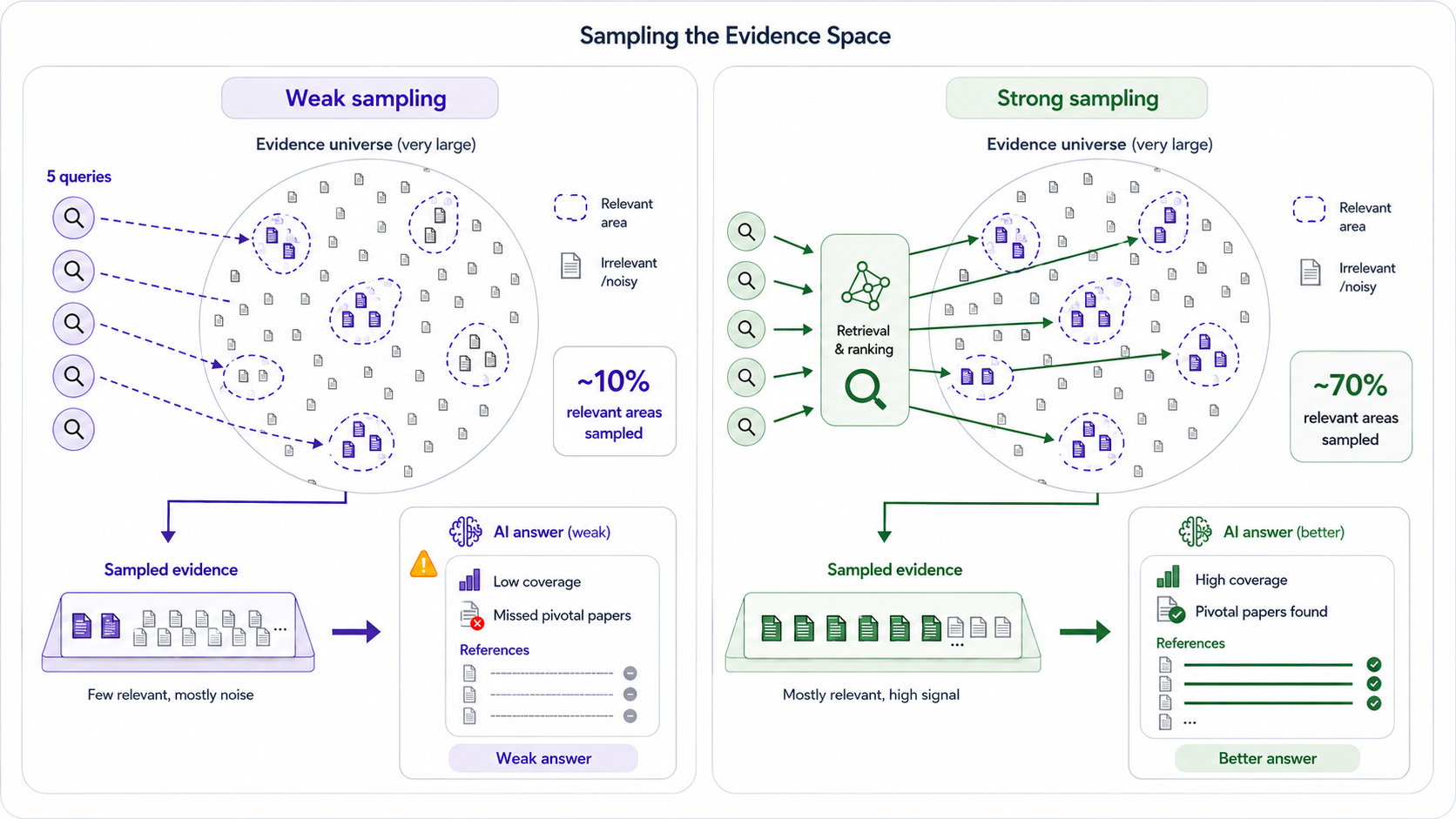
Framed this way, search has a different job: it samples the evidence space until the relevant dimensions are sufficiently covered to support a grounded answer. Returning documents that match the query is the first move, not the finish line. Stopping because the top results look relevant or the citation count feels high and a plausible answer is ready means stopping before that work is done.
What the evaluation found
In an internal head-to-head evaluation on biomedical questions, every system we tested produced a seemingly confident answer. What set them apart was what they retrieved and what they cited. Causaly found 85% of the primary sources a question needed, against 60% and 45% for two widely used general-purpose AI systems. Every source Causaly cited was peer-reviewed literature; for the others, close to a third was news, blog posts, preprints, or database entries. The difference was the search behind the answer.
A team of Causaly biomedical experts ran the controlled evaluation across five biomedical questions spanning virology, immuno-oncology, developmental biology, drug resistance, and neuroscience, with domain experts scoring 643 individual documents by hand. We compared Causaly with two widely used general-purpose AI systems.
Three findings stood out. On recall, Causaly surfaced 85% of the primary sources identified for those questions, against 60% and 45% for the two general systems. On source quality, every document Causaly cited was peer-reviewed scientific literature, compared with roughly 70% for the others, the remainder being news, blogs, preprints, and database entries.
On precision, almost half of one system's citations pointed to papers that mention the topic but never answer the question. All three systems could find the gold-standard paper for each question. The difference was how much of the surrounding evidence each one gathered, and how disciplined it was about what it cited.
How SIRS determines when a search is complete
This is the principle behind our Scientific Information Retrieval System (SIRS). When a scientist asks a complex question, SIRS works out what the question is really asking, maps the evidence dimensions a complete answer depends on, and builds retrieval strategies aimed at each of them.
It searches in passes, broadening and refining until it has evidence across those dimensions, and it records where the evidence is strong and where it is thin. It stops when the space has been sampled well enough to stand behind the answer.
This matters most when the evidence that decides the answer ranks far below the obvious results, like a urine-proteomics biomarker or a treatment-response signal that a keyword search leaves beneath the familiar review articles. SIRS reaches those because it treats them as required coverage, even when no one thought to ask specifically for them. The scientist sees the real breadth of the evidence, and sees where it runs thin, which is information that changes how a finding should be read.
We have written previously about why retrieval is where a trustworthy scientific answer begins and about how Agentic Research is built on top of it.
The question to ask before trusting an AI research tool
Most evaluations ask whether an answer is accurate, well-argued, and backed by real papers. Those checks are necessary and not sufficient, because they all examine the answer and none of them examine the search behind it. The more useful question is whether the response reflects the evidence that exists or only the part that was easy to find.
For teams deciding which targets to pursue and which programs to advance, the stakes are concrete. Evidence you never retrieved still shapes the outcome — it surfaces later, in a trial that fails or a competitor's filing. To test the difference, bring a question from your own research, one where you already know what a complete answer should contain, and evaluate how Agentic Research covers it.
Further reading
.png)

.png)
.png)


.png)


Get started with Causaly
Ready to transform the way your R&D teams discover and deliver? Take the first step - see Causaly for yourself.
Request a demo