What Makes an Agentic Workflow Decision-Ready?
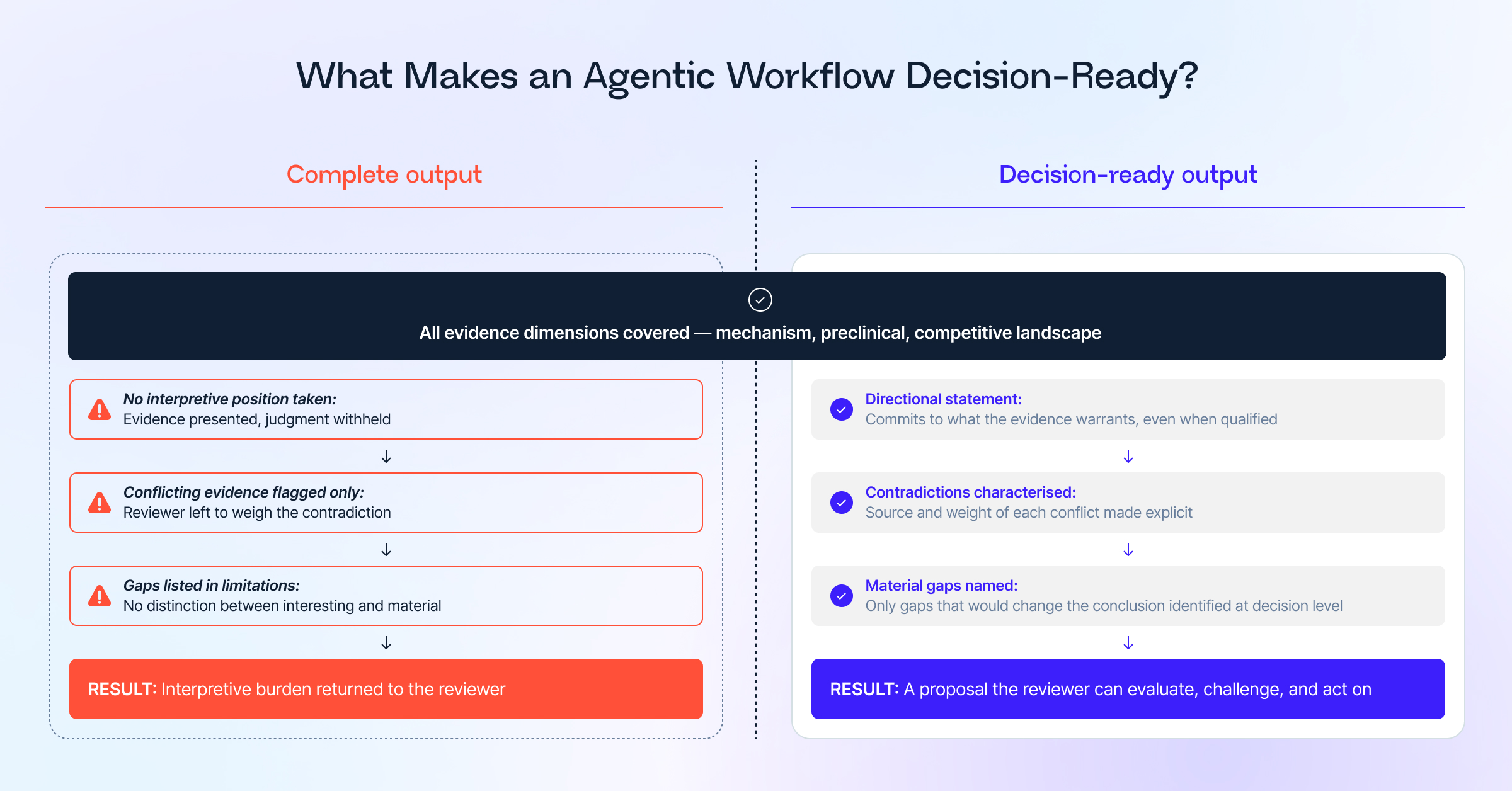
Decision-readiness depends on whether an output takes a position, surfaces the contradictions that matter, and names the gaps that would change the conclusion, not on how much evidence it contains.
.png)
There is a distinction that pharmaceutical organizations rarely make explicit, even though it shapes the usefulness of nearly every evidence output they produce. Completeness and decision-readiness are treated as equivalent, and if an analysis covers every relevant dimension, it is assumed to be fit for review. This assumption fails in ways that are hard to spot and harder to fix.
Consider a go/no-go review scheduled in the morning. The team has prepared a 40-page brief that addresses all relevant dimensions, including the mechanism, preclinical data, competitive landscape, and regulatory precedent. The document is thorough, well-organized, and has clearly required significant analytical effort. A VP reviewing it by evening reads it twice and finds that every piece of evidence is present, but there is no indication of whether the team is recommending progression, flagging a concern, or simply returning the judgment to the reviewer. The document covered everything but resolved nothing.
Decision-readiness depends on whether an output takes a position, surfaces the contradictions that matter, and names the gaps that would change the conclusion, not on how much evidence it contains. An output that does none of these things has summarized the literature without answering the question it was supposed to resolve.
Three elements distinguish a decision-ready output
What a VP or SVP looks for when they open an evidence brief is an evidence-based proposal from the team that conducted the analysis, one that takes a position on what the data means and is prepared to defend it.
Evidence dimensions do not self-organize into arguments. Mechanism, preclinical data, translational evidence, and competitive landscape are inputs that only become a proposal when the analysis commits to a position on what the evidence warrants, and names the conditions under which that position would change. Completeness confirms that the retrieval was thorough, but synthesis is what converts evidence into a recommendation worth reviewing, and three elements mark the difference.
- A directional statement. The output must commit to an interpretation of what the evidence means, and that commitment can be qualified (“The mechanistic case is plausible but not established at human-relevant exposures.”), but it must arrive somewhere. Outputs that hedge every claim without ever reaching a position return the interpretive burden to the person who requested the analysis.
- Explicit acknowledgment and characterization of contradictory or weak evidence. A decision-ready output identifies the evidence that runs counter to the primary conclusion and characterizes the contradiction. But, contradictions cannot always be explained. Is the conflicting signal from a non-representative model? From a study with design limitations? Or from a single observation that has not been replicated? The characterization tells the reviewer how much weight the contradiction should carry. Flagging a conflict without characterizing it leaves the judgment unmade, which is precisely what the output was meant to resolve.
- Identification of the gaps that would change the assessment. Not all gaps are equal, and a decision-ready output makes the distinction explicit. Gaps that are merely interesting belong in a limitations section. Gaps that are material (those where a different answer would alter the direction of the conclusion entirely) need to be named at the decision level. Naming them converts uncertainty from a liability into a structured risk statement, making the output defensible upon review.
Why do outputs that surface their own limitations earn more trust from senior scientists?
Senior scientists are alert to outputs that are too clean. A uniformly positive evidence landscape, with no contradictions, no gaps, and no caveats, is a scientific red flag. Experienced reviewers sense this before they can often articulate why.
Real scientific evidence is uneven. Studies conflict, models fail to translate, and the published literature systematically underrepresents negative findings. An output that presents a tidy picture has either oversimplified the evidence or has not looked carefully enough, and the two are difficult to tell apart until a decision based on that output fails downstream.
An output that names its limitations demonstrates something different. It shows that the synthesis engaged with the evidence at the level required to detect where the argument is weak. That level of engagement is precisely the quality signal senior scientists trust.
Appropriate caution is not a sign of analytical weakness of a system that understands what it found and knows the difference between what the evidence supports and what it merely suggests.
How does decision-readiness look different across workflow types?
The content of a decision-ready output depends on what type of decision the workflow is designed to inform. The three elements apply in every case, but how they apply differs by context.
Safety assessment. A decision-ready safety output delivers a risk characterization, rather than a catalog of adverse events. It must contain:
- An explicit position on each principal signal: plausible, weak, or absent
- The quality and limitations of the evidence supporting each characterization
- The conditions under which the risk becomes material by dose, duration, population, or combination
- Without these conditions, the characterization cannot be acted on.
Indication expansion. A decision-ready indication expansion output centers on a mechanistic argument, tracing the pathway from the compound's mechanism of action to the disease process, stating where the evidence is causal and where it is inferred. It takes a position on whether the mechanistic case is sufficient to justify further investment and names the specific evidence gaps that would need to be closed before that assessment changes in either direction.
Biomarker analysis. A decision-ready biomarker output delivers a feasibility assessment, not a description of available options. It distinguishes biomarker validity and assay validity in the intended matrix and use case. It explicitly names a primary strategy recommendation, ranks adjunctive options, and down-ranks approaches that the evidence does not support, with the reasoning stated. A list of candidates with no ranking is a summary waiting for someone else to finish the work.
The design choice that determines what a workflow can produce
The choice between designing a workflow around coverage and designing it around decision-readiness is architectural, and it determines what the workflow is capable of producing regardless of retrieval thoroughness.
A workflow designed around coverage will produce outputs that are difficult to fault on scope, with every relevant paper and data point accounted for but no interpretive position taken. A workflow designed around decision-readiness will produce outputs that are shorter, more direct, and more defensible, with confidence calibrated to the quality of the supporting evidence and positions that can be challenged, qualified, or overturned as new evidence arrives. That is the output a VP can take into a review and defend.
Senior scientists can evaluate arguments, but they do not have time to construct them from raw evidence at the point of review. The goal is an output that transfers the scientific argument, because the material alone, without an argument, cannot be acted on.
If your organization is thinking about how scientific workflows are designed and what they should produce, Causaly works with R&D teams to build that capability at scale. Request a demo to explore what that looks like for your organization.
Further reading

.png)

.png)
.png)




Get started with Causaly
Ready to transform the way your R&D teams discover and deliver? Take the first step - see Causaly for yourself.
Request a demo