The Identity Layer Behind Better Intelligence
Why drug identity matters for search, landscapes, and AI answers

The problem
Drug development pipelines have an identity problem.
The same therapeutic asset can change names across its development lifecycle: from a lab code in discovery, to an officially recognized non-proprietary name, to a brand name, with additional aliases introduced through trials, publications, licensing, or acquisition.
That problem becomes visible in the execution of knowledge tasks: plotting out a target or indication landscape to support an investment case, finding a key piece of clinical evidence for a broader workflow like target prioritization, or interrogating the latest readouts for a therapeutic asset before a strategy discussion. In each case, the quality of the output depends on whether the system understands which real-world asset is being referenced. If the system searches using only one name, it can miss mentions of the same asset under a different name. The result is an incomplete view of the evidence precisely when the work depends on completeness.
This is easy to overlook as teams become more familiar with fluent outputs from generic LLM systems. A model can produce a confident answer from the information it retrieves, but retrieval depends on identity. A system’s failure to resolve multiple names to the same therapeutic entity can lead to missed evidence, fragmented metadata, and a distorted view of the surrounding evidence landscape.
A human analyst may eventually recognize that these names refer to the same underlying asset. A software system, however, may treat them as distinct entities, fragmenting the evidence and metadata across separate records. That creates more manual reconciliation work for the analyst, undermining the time-savings AI is meant to provide.
This is not a cosmetic data quality issue. It changes what appears in a landscape analysis, which evidence is retrieved, and what an AI system can answer reliably.
Why this matters
Misleading pipeline signals
When the same asset is represented multiple times, a landscape can give a false impression of pipeline depth.
Example: Memo Therapeutics / potravitug

Without identity resolution, these may be interpreted as several distinct assets rather than different representations of the same or related program. That can inflate the apparent size of the pipeline and distort the competitive readout.
The issue is not simply duplication. Fragmented identity creates a misleading market signal: the landscape appears broader and more active than it really is. If this goes unnoticed, it can shape a poor strategic decision. If it is caught, the analyst is pushed back into manual, time-consuming deduplication work.
Missing metadata and evidence
If asset identity is not resolved, metadata and evidence can end up attached to separate records. That makes the complete clinical and development picture harder to retrieve and interpret.
Example: DMT-310 / XYNGARI

Fragmented records mean important metadata is split across entries. Not only is indication and phase information missing, but so is critical evidence.
In this case, missing the aggregation would also mean missing trial evidence from a Phase 1 investigation of the drug in psoriasis. For an analyst building a landscape, that changes the interpretation of the asset: its maturity may be understated, broader indication activity may be missed, and evidence that belongs to the same underlying program may remain disconnected.
Missing evidence leads to weaker AI answers
Identity fragmentation also affects the quality of AI-generated research.
If a question is asked using one drug name, an AI system without a drug ontology may search only that literal name and return a false negative. But clinical data may exist under a different synonym, development code, or generic name.
Example: ALM301 / engasertib
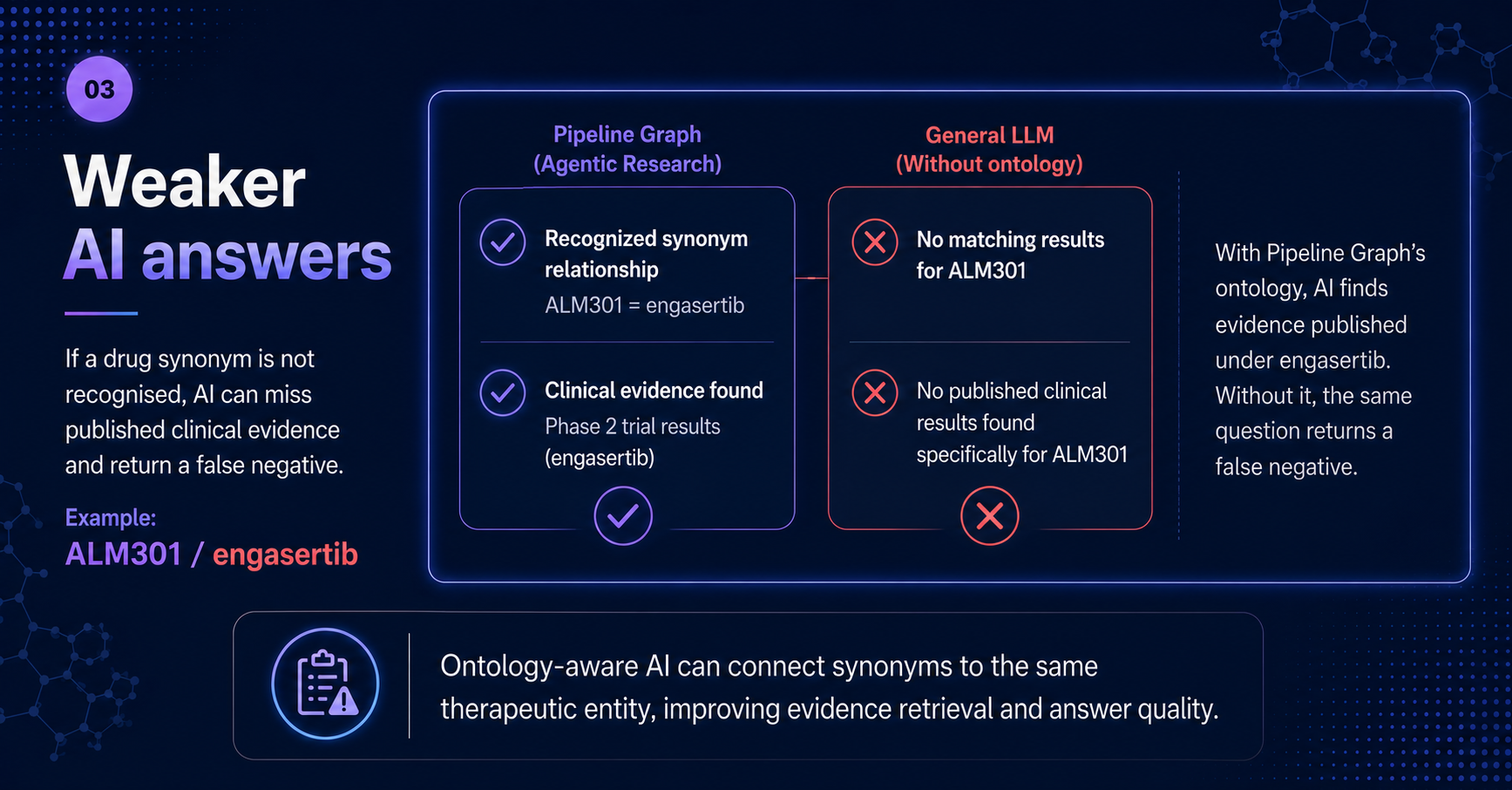
This is the practical difference between a general-purpose foundation model and an agentic research system grounded in a drug ontology.
How Pipeline Graph creates the identity layer
Causaly creates this identity layer in Pipeline Graph, its structured intelligence product for understanding drug development pipelines. (Read more on Pipeline Graph)
The ontology is not a static list of known drug names. It is powered by synonym-finding agents that identify potential relationships between drug names, development codes, aliases, brands, and other identifiers across sources.
Those candidate relationships are checked by a separate validation agent to maintain a high bar for accuracy. Agentic validation is then reinforced by human-in-the-loop review pipelines for cases where precision is especially important, ambiguity is high, or the consequence of an incorrect mapping could materially affect the landscape.
This matters because the risk cuts both ways. Failing to aggregate synonyms can fragment evidence, but incorrectly aggregating distinct drugs can be even more damaging. Mis-aggregation can create false signals, distort landscapes, inflate or suppress competitive activity, and attach the wrong metadata or evidence to the wrong asset.
Pipeline Graph therefore combines agentic synonym discovery, independent agentic validation, and human-in-the-loop review. The goal is to improve recall while preserving a high bar for precision.
The result is a product capability, not only a cleaner backend data model. This identity layer supports better search recall, cleaner asset pages, more accurate landscapes, and stronger AI answers through Causaly’s Agentic Research.
That is the role of the identity layer: using Pipeline Graph’s drug ontology to turn messy, inconsistent drug naming into reliable, connected intelligence.
Further reading
.png)
.png)
.png)


.png)

.png)
.png)

Get started with Causaly
Ready to transform the way your R&D teams discover and deliver? Take the first step - see Causaly for yourself.
Request a demo