Agentification in Biopharma R&D: How To Turn Workflows Into Executable Systems
Agentification in biopharma R&D does not start with agents. It starts with workflow, SOPs, and protocols. Places that already have structure, expectations, and consequences.
.png)
In biopharma R&D, progress is driven less by isolated insights and more by the steady production of decision-grade artifacts. Teams move programs forward by producing things that can be reviewed, debated, and accepted: target assessment dossiers, safety triage briefs, indication expansion analyses, protocol components, and endpoint rationales. These artifacts are the unit of work.
This is where much of the current conversation around agentic AI becomes abstract. Models can retrieve literature, summarize evidence, and generate plausible narratives. While this is useful, it does not automatically translate into enterprise execution. R&D organizations do not need more fluent answers; they need ways to produce the same kinds of artifacts repeatedly, under consistent assumptions, and with a predictable structure.
Start from workflows, not from agents
A pragmatic way to think about agentification is to begin with workflows that already exist and already matter. Across biopharma R&D, core evaluative workflows follow stable patterns even when details vary. Target assessment consistently spans biological rationale, human genetics, expression context, mechanism, class precedent, safety liabilities, tractability, and the competitive landscape, with emphasis shifting by role and program stage rather than by structure.
Safety triage is similarly patterned, moving from signal characterization and plausibility assessment through class effects, population relevance, and explicit articulation of uncertainty and next steps. Indication expansion sits between these two, combining a reassessment of biology and risk in a new disease context, with continuity of what is already known about the underlying mechanism and modality.
They are structured evaluations with implicit standards for completeness and rigor. Humans execute them by following mental runbooks developed through experience. Agentification, at its most useful form, is about making those runbooks explicit.
From questions to executable work
Most AI systems are optimized for answering questions. In R&D, the question is rarely the hard part. The hard part is executing the work consistently. A prompt like “Assess whether target X could be viable in lupus” captures the objective, but not the execution logic. Is this early exploration or late-stage prioritization? How conservative should the safety assessment be? Which evidence dimensions are required versus optional? What level of uncertainty is acceptable?
Humans resolve this ambiguity through context and experience. A system cannot do the same, unless that structure is made explicit. The practical shift is to stop thinking in terms of “asking better questions” and start thinking in terms of defining the work product. What artifact should exist at the end? What sections must it contain? What evidence must be checked? What assumptions must be surfaced?
Once that is clear, the role of an agent changes: it is no longer improvising an answer. It is executing a defined piece of work.

The mechanics that make agentification viable
Across real deployments, a few key mechanics determine if agentification compounds or stalls;
- Explicit task definitions
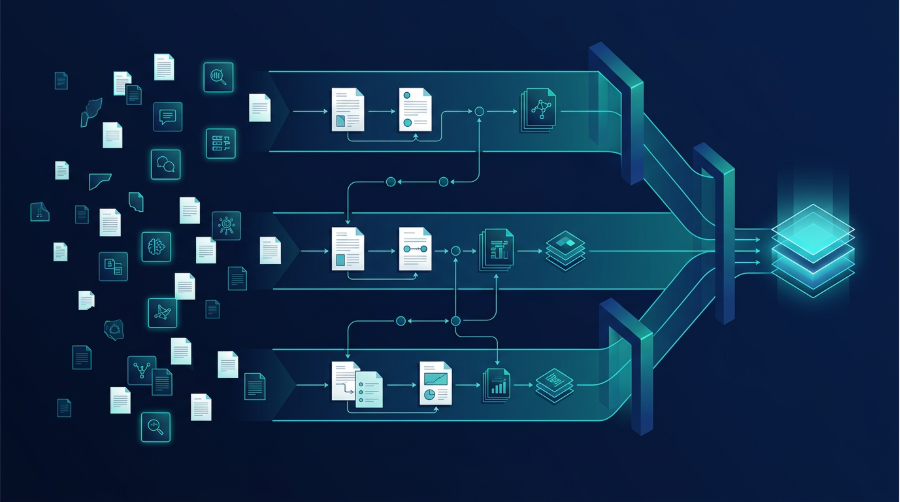
A production workflow is not a prompt. It is a specification: required inputs, evidence dimensions, expected outputs, and review criteria. For a target assessment, that might mean a ranked target table, an evidence grid by dimension, and an explicit assumptions and limitations section. - Deterministic intermediate artifacts
Good workflows generate checkpoints: evidence tables, risk matrices, and mechanism summaries. These artifacts make the work inspectable, reduce review costs, and prevent agents from jumping to conclusions. - Clear termination conditions
An agent should stop once the work is complete, not because it has run out of ideas. Completion should be tied to defined criteria: all required sections populated, evidence coverage achieved, uncertainty articulated. - Context that constrains execution
The same workflow executed by a translational scientist, a safety physician, or a portfolio lead should emphasize different aspects. Likewise, organizational context, existing portfolio, mechanism experience, risk posture, should shape how conservative the execution is. Without explicit context, variability creeps in. - Reusability over novelty
The value comes from doing the same work better and faster the tenth time, not from producing a clever one-off analysis. Workflows that cannot be reused across teams and time do not scale.
None of this requires autonomy in the abstract. It requires structure.
The impact of well-executed agentification
When agentification is grounded in real workflows and executed with a clear structure, the effect is not primarily better answers, but more reliable execution. Core activities such as target assessment, safety triage, and indication expansion begin to produce artifacts with consistent structure, evidence coverage, and explicit assumptions, regardless of who initiates the work or when it is run.
Review becomes faster because outputs are predictable and inspectable, and decisions rely less on reconstructing the processes and more on evaluating the substance.
Over time, this consistency turns tacit expertise into organizational capability. The way experienced scientists assess mechanisms, weigh evidence, or flag risks is no longer confined to individuals or informal practices. It becomes embedded in executable workflows that reflect how work is actually done, not how it is described in theory.
As a result, high-value know-how is reused across teams and therapeutic areas, without requiring constant involvement from the same senior experts.
Agentification also reduces friction caused by fragmented tools and ad hoc execution. When workflows are explicit, changes in assumptions, standards, or external conditions can be incorporated centrally rather than rediscovered repeatedly. Outputs remain aligned as models evolve, or new data arrives because the structure of the work stays stable even as the content changes.
Most importantly, work begins to compound rather than reset. Each execution produces an artifact that can be reviewed, reused, and updated, rather than discarded as a one-off result. Scientific reasoning carries forward across sessions and across people, and cycle time compresses without lowering scientific standards. In this form, agentification functions less as a productivity layer and more as infrastructure for durable, scalable R&D execution.
In conclusion
Agentification in biopharma R&D does not start with agents. It starts with workflow, SOPs, and protocols. Target assessments, safety triage, and indication expansion are good places to begin because they already have structure, expectations, and consequences.
Making that structure explicit, and executable is what allows AI to support real decisions, not just generate plausible text. What will distinguish leading R&D organizations is not how often they use AI, but how deeply it is embedded in executable workflows that turn individual efficiency gains into durable, enterprise-level R&D performance.
Further reading






.png)
.png)

Get started with Causaly
Ready to transform the way your R&D teams discover and deliver? Take the first step - see Causaly for yourself.
Request a demo