Why Enterprise AI Needs More Than Coding Agents in Life Sciences
The conditions that make AI coding feel effortless are mostly absent in biomedical science. That gap defines what enterprise R&D leaders should build for.
.png)
If you have spent a weekend with Claude Code or Codex, you have probably felt the same excitement that many people in our industry felt this year. You describe what you want, the agent writes it, tests it, and runs it. It is easy to conclude that every knowledge worker is about to be transformed in the same way, on the same timeline.
Aaron Levie, CEO of Box, made a sharp observation about this on a recent podcast. His point is that coding works so well for agents because it is a very specific kind of work done by a very specific user, and that does not mean the same results carry over to every knowledge worker in an enterprise.
A lot of unique problems still have to be solved everywhere else. The lesson for drug discovery and development is that the coding paradigm does not transfer cleanly, and understanding why tells you what you actually need to build.
Why coding is the “easy” case
Aaron walks through what he calls a ledger of reasons that software engineering is the friendliest possible setting for agentic AI:
- The person driving the agent is highly technical, so when the agent does something wrong, they can diagnose it and get it back on track.
- The models are disproportionately trained on code, so raw capability is high.
- The work is verifiable because the code either runs and passes its tests, or it does not.
- The user is wired into the ecosystem and adopts new techniques quickly.
- Most of the relevant context lives in one place: the codebase, often small enough to fit in a model's context window.
- And engineers usually have clean, generous access to the repository they work on, so the agent can consume what it needs and produce output freely.
However, the same properties that make coding the easy case are what the rest of the enterprise lacks, and that is exactly why the benefits do not spread evenly. These reasons explain why diffusion across the rest of the enterprise will take years rather than months.
These are the dimensions I want to test, so before going further, it helps to see them side by side in the table below: the factors that make coding the “easy” case, and how those same dimensions look in drug R&D. The rest of the post walks through each row, starting with where general models break down on scientific meaning.
General models confabulate the terms science depends on
Frontier models are far less saturated on biology than on code, and much of the real signal lives in proprietary assays and paywalled literature rather than on the open web. Scientific meaning depends on ontologies: the way drugs and their synonyms are organized, the way genes and gene symbols map to one another, and the internal terminologies each organization carries.
General models confabulate these relationships because they were never trained specifically to solve them. Science needs special-purpose machinery rather than general search: scientific information retrieval over a curated data fabric, and knowledge graphs that hold the mechanisms, targets, and relationships that matter in biology.
At Causaly, that fabric spans roughly 40 million abstracts and full texts, 500,000+ trials, 1.6 million patents, and a dozen MCP connectors, with two knowledge graphs encoding hundreds of millions of biomedical facts and the ontology grounding that keeps a gene a gene and a synonym a synonym.

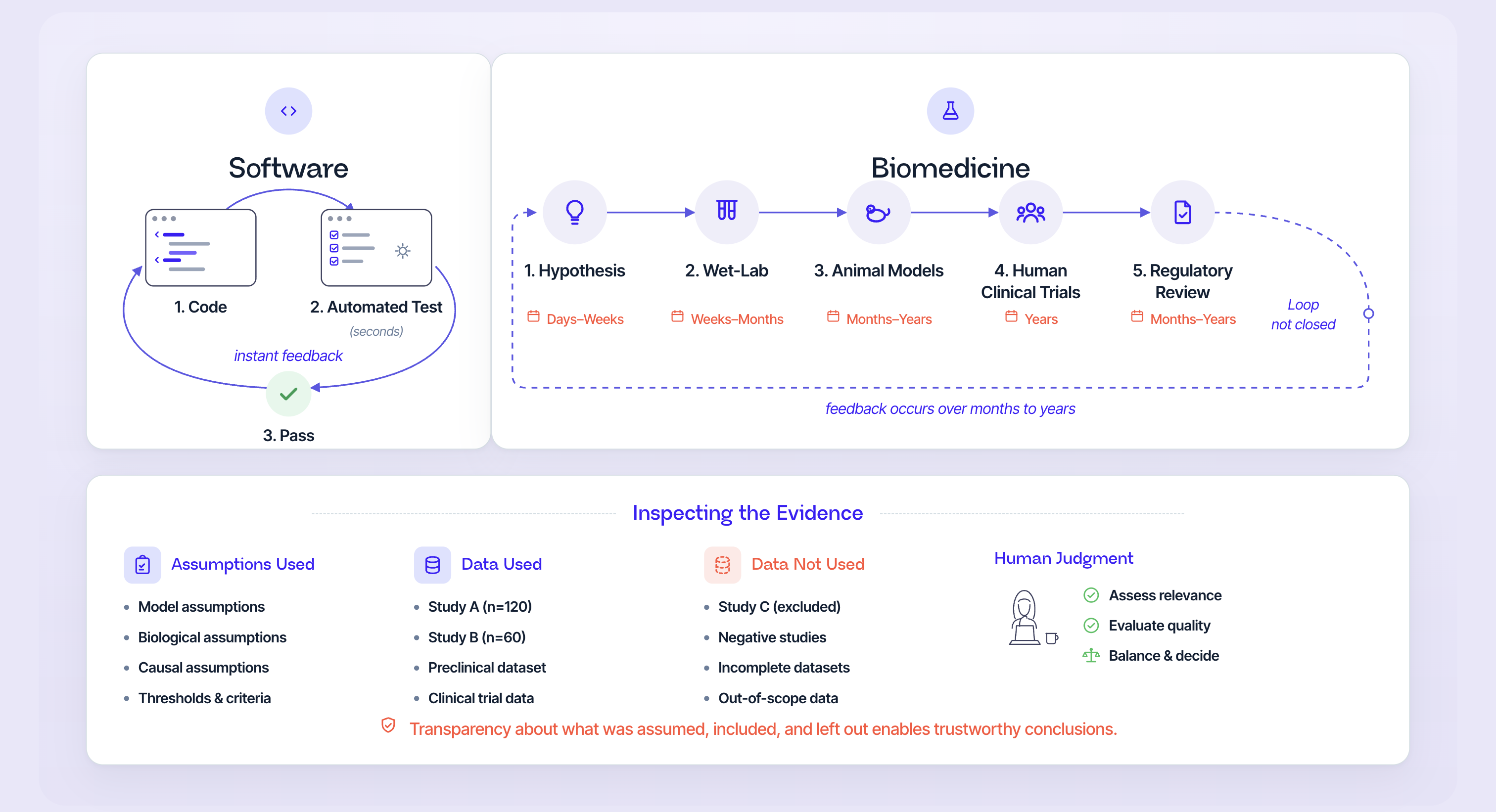
Verification is open in biology, so everything must be inspectable for the human user to exercise judgement
This is the deepest difference between coding and biomedical science. In coding, verification is a closed loop: a test passes or fails, and you know immediately. In biomedicine, that loop does not close just in silico. Whether a protein target truly drives a disease is settled by wet-lab work, then animal models, then humans, over months and years.
A safety review is judged against regulatory standards and real adverse-event data. Even with a lab in the loop, the process remains open-ended in clinical studies. Human clinical trials have no high-throughput shortcut, and a response to a health authority needs full verifiability before it can be submitted.
When a system cannot verify an answer, the next best thing is to make everything about that answer inspectable, so the scientist can close the judgment loop themselves. This is the key. That means showing the assumptions the system made, the data it used, the data it did not use, and whether evidence such as genetic information was actually considered.
Consider target identification and prioritization, where confidence in a target or pathway can rest on a dozen or two dozen dimensions of evidence. If a model weighs only two of those twelve, it is missing evidence it should have used, and a fluent paragraph will hide that gap. Showing the scientist the full picture of what is known and what is missing is what lets them exercise judgment and build it over time. We think of this as closing the judgment loop, which is why sentence-level provenance and a visible trail of assumptions sit at the core of the product.
The technical user becomes the domain expert
In drug R&D, the user is a biologist, a medicinal chemist, a clinical scientist, or a safety reviewer. They have deep scientific judgment, but they are not fluent in agent mechanics. When an agent proposes a hypothesis or drafts a protocol section that looks plausible but is subtly wrong, catching it is harder, and the stakes are higher.
This is why we built an embedded scientific enablement team of our own PhDs and MDs. These science liaisons sit alongside customer scientists, coach them, co-design the workflows, and show them how to apply the tools to real decisions, supported by a self-learning portal. The expertise an engineer brings for free has to be deliberately built into the way scientists work.
The interface is how non-technical users stay in control
Engineers absorb best practices from the ecosystem and will quickly edit a skills file. A non-technical knowledge worker will not open a skills file and author skills, and that is the right expectation for the foreseeable future. This is why the user interface matters so much. Even if the model made perfect choices in the background, the scientist still needs those choices to be visible and understandable, because the output does not self-verify the way compiled code does.
A guiding interface that surfaces the assumptions and nudges the user toward sound choices is what makes judgment possible at the end. Causaly is workflow-native for this reason, with prebuilt and configurable workflows for tasks like target biology, target-disease association, and toxicology assessment that encode best practice into repeatable, governed steps.
Context is scattered across people, not gathered in a repository
In coding, most of the context lives in the codebase, and the relevant parts of a codebase often fit in a context window. In an enterprise, that is not the case, and in a discovery or development organization, it has highly complex, fragmented, expert knowledge. It is even more extreme. The medicinal chemist, the biologist, and the medical director each hold a different lens on the same objective, which is how to develop a drug that is both efficacious and safe.
The context is individual, team-based, and department-based, and it lives in documents and in tacit knowledge. Knowledge graphs help map the parts that can be structured, and Causaly integrates proprietary data, licensed sources, custom ontologies, and internal tools into one shared workspace. The part that stays tacit is where humans coordinate and exercise judgment, which makes keeping humans in the loop more essential than optional.
Access control is a regulatory constraint, not a convenience
An engineer typically has access to the whole portion of the codebase they need, so the agent inherits that access. Drug R&D is among the most permission-constrained environments anywhere, with patient data under HIPAA and GDPR, blinded trial data, firewalls between programs, and GxP audit requirements. An agent here will hit entitlement walls, or, worse, reach data it should never have touched.
That is why governance sits inside the system: secure integration of proprietary data, orchestration with traceability, model-routing policies, full audit trails, and source provenance on every conclusion, so that agentic work runs inside the customer's compliance boundary.
What this means for leaders
A new way of working and a new class of tools always take a long time to penetrate and grow through an organization, and structured transformation programs are what make adoption happen at scale. The encouraging part is that this difficulty is also the opportunity. The teams that move first will be the ones that treat the harness around the model as the real product.
If you lead R&D, or the IT function that supports them, here is what the work calls for: A general agent pointed at scientific work will fall short. What the work needs is science-purpose retrieval and ontology-aware knowledge graphs, inspectable provenance so scientists can close the judgment loop, a guiding workflow interface rather than a prompt box, enterprise-grade governance, and a human enablement program that drives the change.
In the last six months, coding showed the industry how good agents can be and how this type of knowledge work is changing. Life Sciences and specifically Drug discovery & Development show what it takes to make them trustworthy, where the answer is measured by patient safety rather than by passing tests.
Source referenced in this post: Aaron Levie on “State of Enterprise AI 2026,” The MAD Podcast with Matt Turck, May 28, 2026,
Further reading



.png)

.png)


Get started with Causaly
Ready to transform the way your R&D teams discover and deliver? Take the first step - see Causaly for yourself.
Request a demo