What a Trustworthy Target Safety Assessment Workflow Actually Looks Like
A workflow that fails to engage the human genetic evidence layer is missing the dimension with the strongest predictive value for human safety outcomes, however thoroughly it may cover the remainder of the literature.
.png)
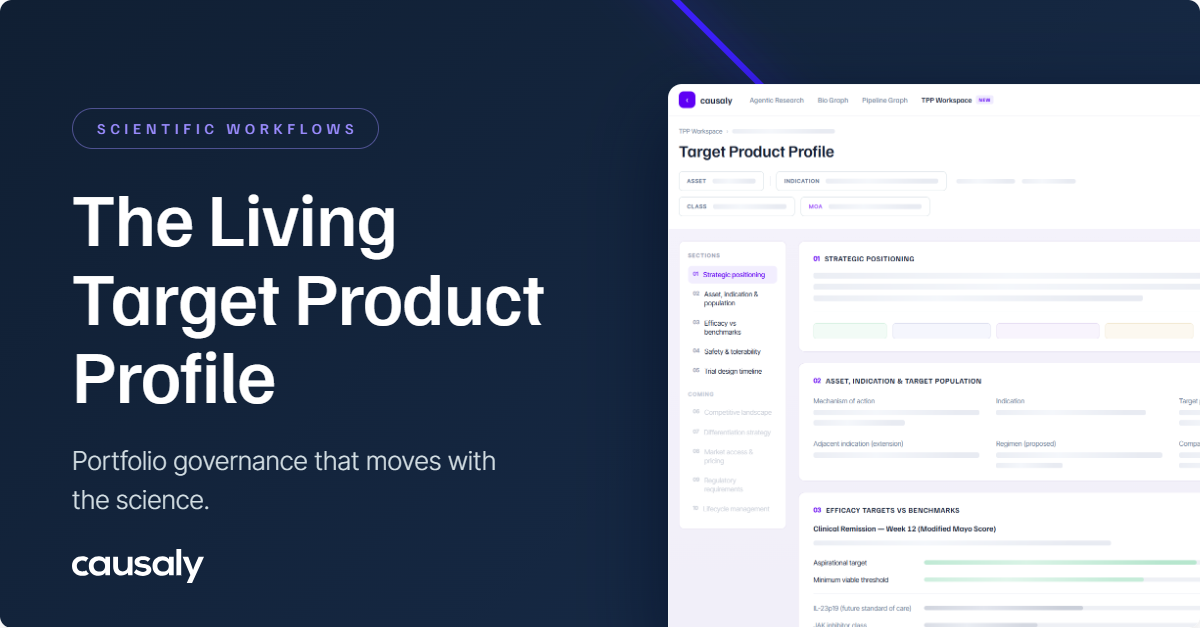
Senior drug development teams routinely produce safety assessments that meet all formal requirements, yet fail to support the decisions they were built to inform.
The outputs compile references, address each required domain, and draw on an extensive body of evidence, but portfolio committees find themselves making go/no-go calls on targets where the scientific basis for the safety conclusion remains unclear. The gap between a compliant output and a decision-grade one is methodological in origin, and with deliberate workflow design, it is fixable.
A trustworthy safety assessment workflow possesses three defining properties:
- presenting evidence within a defined hierarchy,
- engaging with contradictions instead of smoothing them into a single agreeable narrative,
- and stating uncertainty in calibrated terms.
These are scientific requirements with measurable consequences at the portfolio level, and they remain independent regardless of how much the workflow retrieved or how comprehensive the output appears.
Evidence Hierarchy in Safety Assessment
Senior safety scientists evaluate workflow outputs primarily on which categories of evidence are present and how those categories are weighted, with the below three dimensions consistently dominating that evaluation.
- Human genetic evidence carries the greatest interpretive weight, because naturally occurring variants in a target pathway constitute - in the framing established by Plenge, Scolnick, and Altshuler in Nature Reviews Drug Discovery - experiments of nature that reveal what happens when target function is perturbed in the organism where the drug will eventually act.
Animal models contribute meaningful context, though their predictive validity for human safety endpoints has been well-documented as limited, and this limitation is precisely what gives human genetic signals their distinctive value as a complementary line of inquiry. subsequent review in the same journal, authored by industry safety scientists from AstraZeneca, Pfizer, Novartis, and Merck, has formalized the principle for safety assessment.
In particular, Carss and colleagues describe how human genetic variation can be used to anticipate on-target adverse events, assess carcinogenicity risk, and design translational safety studies in ways that conventional preclinical models cannot reliably approximate.
A workflow that fails to engage this evidence layer is missing the dimension with the strongest predictive value for human safety outcomes, however thoroughly it may cover the remainder of the literature.
- Tissue selectivity occupies the next layer of the hierarchy, because the distribution of target expression across normal tissue types determines the scope of potential on-mechanism effects outside the intended disease context. A target expressed selectively within disease-relevant tissue presents a substantially different risk profile from one expressed broadly across multiple organ systems.
An output that omits this level of expression analysis has left a primary safety question unanswered.
- Mechanistic class precedent completes the picture, since compounds operating through a shared mechanism frequently share safety liabilities. Prior experience with related molecules constitutes directly relevant evidence for anticipating what a new compound is likely to do once it reaches patients.
Omitting this dimension forfeits information that is generally available and frequently consequential, particularly when class effects have already manifested in late-stage clinical work where the cost of rediscovery is at its highest.
Taken together, these three categories represent a strong foundation for trustworthy safety assessment, though the precise configuration will vary by modality, therapeutic area, and organizational context, with species translatability, biomarker availability, and platform-specific risk considerations all representing evidence dimensions that many organizations appropriately treat as equally primary.
.png)
What remains consistent across these configurations is that volume alone cannot substitute for genuine engagement with the dimensions most relevant to the program at hand, and an assessment can be lengthy, well-referenced, and externally credible while still falling short of the evidentiary standard required to support a defensible safety conclusion.
Why Retrieval Volume Misleads
A persistent design error treats comprehensiveness as a proxy for rigor, and while the assumption that more sources produce a more reliable assessment is intuitive, it does not hold when applied to how safety evidence behaves .
The analytical capacity a trustworthy workflow must encode is the ability to separate directionally significant signals from incidental ones, and that separation requires explicit interpretive weighting.
Human genetic evidence carries greater weight than mechanistic in vitro data that lacks clinical context. While prospective human findings carry greater weight than single-species animal observations.
These weights reflect documented differences in predictive validity that have proven stable across therapy areas. The judgments encoded in such weighting are empirical claims about the strength of different evidence types, and they are sufficiently stable to be operationalized in workflow design without recourse to individual discretion.
When a workflow retrieves broadly without weighting, the interpretive burden shifts onto the reviewer, and two reviewers examining the same retrieved evidence may reach different conclusions, because each may apply an implicit standard the workflow itself failed to specify.
..png)
The resulting variation in conclusions across programs is easily mistaken for scientific disagreement, when its actual origin lies in methodological inconsistency. This distinction matters considerably for portfolio committees attempting to compare assessments that were produced under methodologically divergent standards.
A well-designed workflow encodes the weighting logic in its architecture, so that scientific judgment is applied consistently across every run, regardless of who conducts the analysis.
The output becomes reproducible in a meaningful sense, and it can be interpreted against a standard visible to every reviewer, rather than residing solely in the experience of individual scientists.
Portfolio-Level Consequences
The purpose of a safety workflow output is to place a portfolio committee in a position to decide, and that decision requires both clarity about what is known and clarity about what is not, with both produced by the workflow itself.
A committee that performs the analytical work after reviewing the output is operating with an incomplete deliverable, and over time, the gap compounds into inconsistency across the portfolio that no single decision can fully repair.
When workflows produce outputs of this standard consistently across programs, teams, and therapy areas, the variation in safety conclusions across the portfolio begins to reflect genuine differences in what the evidence shows.
This methodological inconsistency, that currently masquerades as scientific disagreement, disappears. Reviewers can direct their attention to the science itself, the basis for each conclusion remains visible, and the committee's decisions become defensible in ways that depend on the system, instead of depending on the presence of specific individuals.
The scientific infrastructure to support this standard is already in place. Human genetic databases have matured considerably over the past decade, tissue expression atlases have expanded in coverage and accessibility, and clinical compound precedent is more readily available to be queried now than at any prior point in the industry's history.
The differentiating factor at this stage is workflow architecture, and the operative question for any organization is whether these resources are being deployed within a structure that enforces an evidence hierarchy, requires engagement with contradictions, and produces outputs designed to support decisions with traceable scientific reasoning.
For an industry in which the cost of a misjudged go/no-go decision is measured in years and hundreds of millions of dollars, the case for building that architecture with deliberate care is straightforward, and it warrants the sustained investment that careful design requires.
Further reading






.png)


Get started with Causaly
Ready to transform the way your R&D teams discover and deliver? Take the first step - see Causaly for yourself.
Request a demo