From Data to Insight: Where Agentic AI Moves Next in R&D
When agents can write and run code well, the evidence system can begin at the point of data generation, not only at the point of decision.
For most of the past two years, the conversation about AI in life sciences R&D started after the data already exists. A scientist has a result, a paper, and the question is how to reason over it. While evidence systems have earned their place there, it skips a step that happens earlier and consumes a large share of expert time, which is turning raw measurements into a signal worth interpreting at all.
That earlier step is now reachable, for a specific reason: AI agents have become good at writing and running code. When an agent can plan an analysis, write the script, execute it, read the output, and correct itself, it can take on a class of work that used to sit with a bioinformatician or a computational biologist.
The argument I want to make is that agents that code well let us address the point of data generation, and not only the point of decision, which expands both where Causaly is useful and what an evidence system is responsible for.
The opportunity of data interpretation and scientific computation
It is worth being clear about what data generation means and why a large set of R&D use cases depend on it. By data generation I mean the raw experimental and clinical measurements an organization produces: the output of an instrument or an assay before anyone has turned it into a result.
This data is high-dimensional, often messy, and rarely ready to read. It sits between the experiment and the conclusion, and a computational step has to happen before a scientist can reason about it.
This is important because much of this work begins here. A wide set of use cases is founded on first, computing a signal from generated data, and then interpreting that signal scientifically. The table below pairs common data-generation sources with the downstream interpretation work they enable.
In each row, the pattern is the same: raw data is generated, a computational step extracts a signal, and a scientific reading turns that signal into a decision. The distance between a raw dataset and a defensible reading of it is what has slowed all of this. That gap is exactly what coding-capable agents now help close.

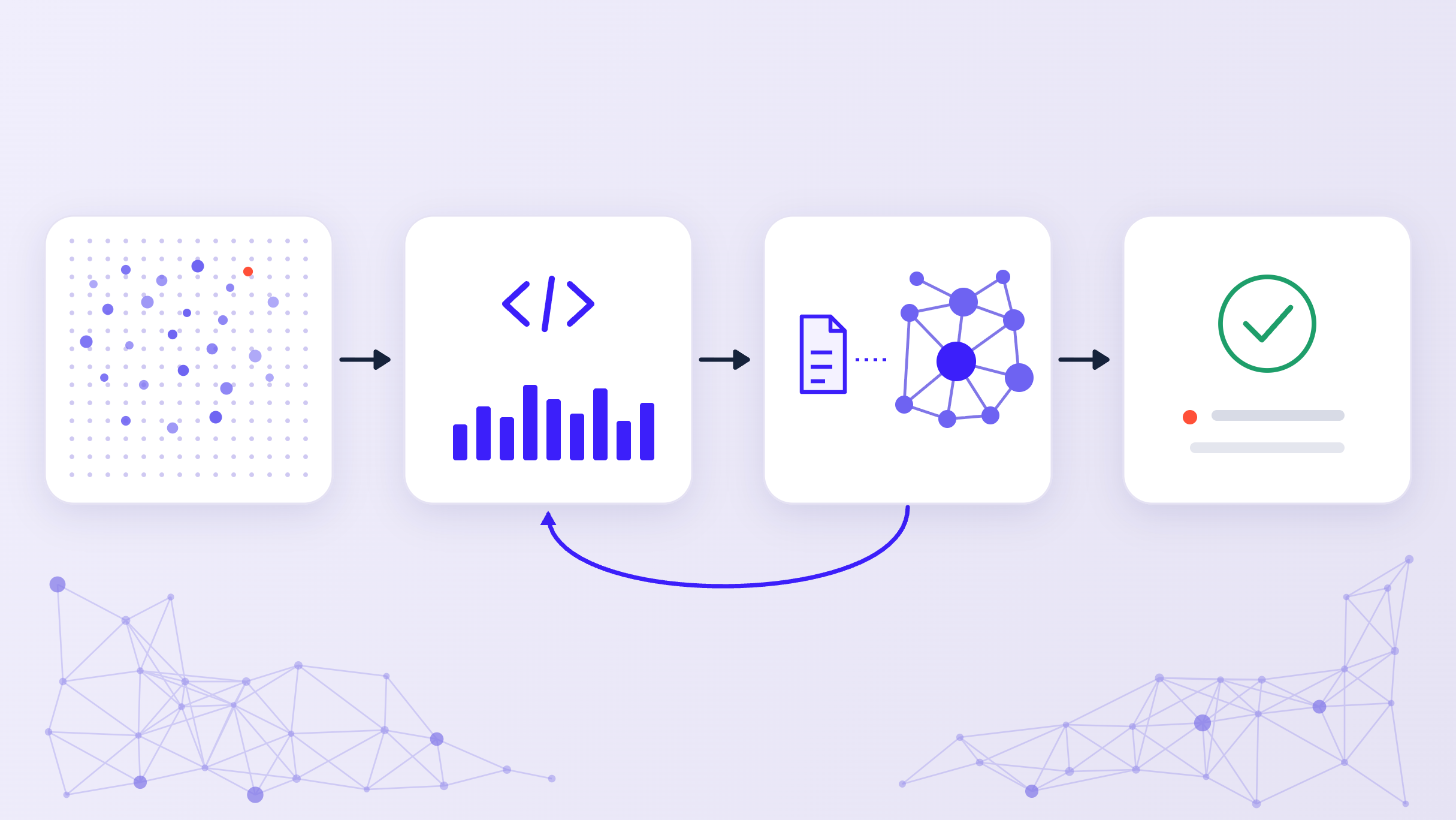
How the pathway from data to insight works
It helps to be concrete about the pathway, because each stage has a different character.
It begins with data: raw, high-dimensional, and rarely ready to read. From there, we compute the signal, through normalization, quality control, differential analysis, and model fitting, which converts measurements into something a scientist can reason about.
Agents that write and execute code can now do much of this transparently, showing the steps, the parameters, and the intermediate outputs instead of returning a single number.
Then we interpret the signal scientifically. A differential result or a cluster is not yet a conclusion, because it has to be placed against prior biology, mechanism, known liabilities, and the organization’s own history with similar programs.
Causaly Agentic Research handles this stage, retrieving the relevant external and internal evidence and assembling a structured, cited reading of what the signal means. This is the same shift toward reviewable artifacts and away from fluent answers that we described in our view of how AI in R&D moves from copilots to agentic workflows.
Interpretation often sends you back to compute, because the first reading raises a question the first analysis did not answer, so the agent runs another, refines a threshold, or tests an alternative model, and the cycle repeats.
Only after the signal and its interpretation have settled do we synthesize: a reviewable artifact that states what was found, what supports it, what contradicts it, and what to do next. The sequence is data, compute, interpret, compute again if needed, and synthesize.
The loop itself is familiar but what is new is that an agent can now carry real weight at the compute stage and connect it directly to the interpretation stage in one governed workflow, which is why our recent collaboration with Microsoft is built on this principle, connecting large-scale scientific computation to scientific so that compute generates quantitatively supported signals from internal data, and the evidence layer judges whether those signals are biologically meaningful and consistent with what the organization already knows.
The opportunity for R&D CIOs
For a head of research, the relevant shift is reach. Work that previously required scarce computational specialists for every exploratory question can now be initiated by the scientists who own the biology, with agents doing the analysis under their direction. For an R&D CIO, the shift is larger, and it changes how the enterprise should think about the data it already owns.
The sub-thesis I want to put in front of CIOs is that the agent's ability to code, combined with scientific computing and the organization’s own data, opens a new paradigm. All the raw data that already exists inside the enterprise, data that was interpreted once in the context of a single indication, can now be reinterpreted at scale for many other indications.
A proteomics run analyzed years ago for one disease carries a signal relevant to several others, and until now, the limit on extracting that signal was human: how many datasets a finite number of specialists could revisit and read. That limit is what changes. When agents can compute and interpret under governance, an organization can reuse its existing data across diseases at a scale that was never available before, and that reuse becomes a genuine competitive advantage.
This is valuable only if every step stays transparent: the code that produced a signal, the evidence behind an interpretation, the assumptions that were made, and the points where a human made a call. This is the same principle we have argued for in coding contexts, where the right response to work AI cannot fully verify is to make every step inspectable so the scientist can close the judgment loop.
It holds even more firmly at the point of data generation, where a hidden choice in an analysis can quietly bias everything downstream. The same capability that lets agents codify expert methods into repeatable scientific workflows now lets those workflows begin at the raw data, run the computation, interpret the result, and produce something a review board can stand behind.
The path from data to insight becomes one governed line of work rather than a series of handoffs between tools and teams. That is the paradigm we are building for, and it starts much closer to the data than the industry has been willing to go.
Further reading
.png)

.png)
.png)


.png)

.png)

Get started with Causaly
Ready to transform the way your R&D teams discover and deliver? Take the first step - see Causaly for yourself.
Request a demo