From Copilots to Agentic Workflows: How AI in R&D Changes in 2026
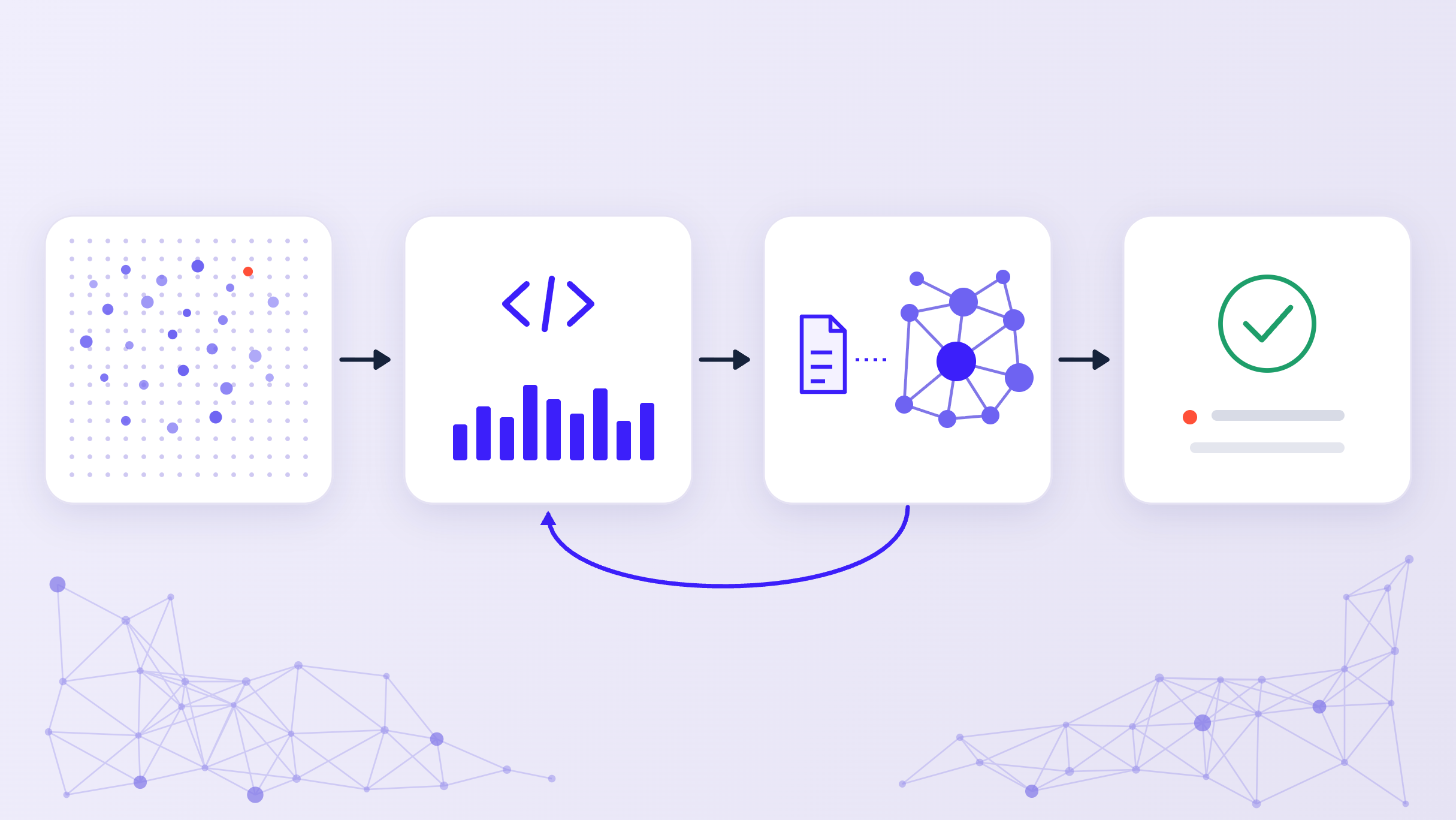
In 2026, the wedge will be who can turn scientific work into executable units—use cases and workflows that are decomposed into precise steps, run with predictable structure, and produce reviewable artifacts with provenance.
%20(14).png)
A few years ago, “AI in R&D” mostly meant better search paired with a chat interface. The shift was from keyword search to semantic search, layered with retrieval-augmented generation (RAG), producing systems that could retrieve relevant documents and draft plausible summaries. Then came “deep research” behaviors: multi-step decomposition, tool use, and evidence synthesis. These developments all belong to the same era: copilots that accelerate humans by retrieving and summarizing information, sometimes with impressive multi-step reasoning, but still lacking a stable execution contract.
What’s changing now is that we’re moving from individual productivity to automation.
- Phase 1 (the last few years): Copilots + deep research.
Search → RAG → tool-using investigations. Great for accelerating individuals, but limited when you need repeatable, reviewable artifacts with predictable structure such as a target assessment report. - Phase 2 (today → next 6–12 months): Agentification of workflows
One-off investigations are being turned into executable, governed units of work: explicit specs, stable outputs, defined steps, and evaluation harnesses.

Phase 2 (today → next 6–12 months): Agentification
“Agentic AI” is often framed as a model that can reason and use tools. That’s correct, but it’s not the real bottleneck for “agentifying” enterprise workflows. The bottleneck is that enterprises need predictable execution inside workflows.
A useful analogy is what we are already seeing in agentic coding tools like Cursor and Claude Code. The strongest models can code for multiple hours and solve complex problems but only when three things are in place:
- A specification up front (intent, constraints, acceptance criteria).
- High-fidelity context (prior decisions, internal enterprise data, semantic memory)
- A harness and scaffolding that enforces predictable outputs (“Always create these seven sections for my report”)
Agentification in pharma R&D is conceptually the same. If you want AI to execute “biomarker inclusion logic” as a repeatable use case - or string multiple use cases into a workflow like protocol drafting - you will need explicit specs, reliable context, and execution harness.
Use cases versus workflows: the operational distinction
In pharma R&D, a workflow is the business process that produces a real artifact and undergoes review. Protocol drafting in clinical development is a canonical example.
Within that workflow sit multiple use cases: endpoint selection, biomarker rationale, inclusion/exclusion logic, comparator choice, statistical considerations, safety monitoring rationale, and more.
Each use case can itself be multi-step. Endpoint selection is not simply “find endpoints.” It involves interpreting indication context, aligning with precedent trials, mapping to regulatory and payer expectations, identifying validated instruments, evaluating sensitivity to change, and justifying trade-offs given operational constraints.
Deep-research systems can support parts of this today, but typically as a one-off run: you ask a question, the system investigates, and it returns a narrative. That’s helpful, but it does not yet behave like an enterprise-grade unit of work.
What “productionizing a use case” actually entails
1) The output becomes a governed business artifact, not a narrative answer
In real workflows, format is part of the contract. If your endpoint rationale document has 10 required sections, it must return 10 sections every time with same headings, same ordering, same minimum fields, so it can enter a review process. It cannot drift from 9 to 12 sections based on the model’s internal sampling. This pushes systems toward schema-driven generation: templates, required fields, explicit evidence tables, assumptions, and limitations. The model still writes, but it writes into a frame.
2) The execution plan becomes explicit, testable, and replayable
A production use case is not a prompt. It’s closer to an SOP: a defined sequence of steps, tools, evidence checks, and stop conditions. In practice that means:
- a fixed investigation plan (or a constrained plan space),
- deterministic intermediate artifacts (evidence tables, characterization grids),
- and explicit termination conditions tied to the purpose of the run.
Termination conditions are not academic. Without them, systems either stop too early (missing critical evidence) or keep refining forever (wasting time and producing unstable outputs). Neither maps to enterprise workflows.
3) Variability shifts from “model creativity” to “organization configuration”
Enterprises are heterogeneous. Two companies may both run “biomarker inclusion logic,” yet trust different internal sources, weight evidence differently, route review to different stakeholders, and set different thresholds for what counts as “sufficient evidence.” So the system has to support controlled customization: authoritative sources, permitted tools, mandatory evidence dimensions, and explicit pass/fail criteria. That configuration becomes part of the product.
4) Retrieval quality (“Search”) becomes even more decisive
When you move from one-off Q&As to workflow execution, retrieval failures compound. A workflow agent that pulls the wrong evidence at step two contaminates steps three through ten. So even as the industry conversation fixates on agents, the winners will still be the systems that treat scientific information retrieval as a first-class capability: full-text coverage, granular provenance, ontology/graph grounding, and ranking optimized for decision-relevant signal rather than convenience.
What “automation” means in Phase 2
In 2026, no R&D organization will jump directly to autonomy. The near-term shift is from productivity tooling (helping a scientist go faster) to automation of bounded use cases (completing a defined unit of work) and then to orchestration into workflows that yield reviewable artifacts.
What R&D and CIO leaders should be looking out for in 2026
In 2026, the wedge will not be “who has the best model.” The wedge will be who can turn scientific work into executable units—use cases and workflows that are decomposed into precise steps, run with predictable structure, and produce reviewable artifacts with provenance. To get there, two things matter more than most organizations currently assume.
1) Workflow decomposition is the bottleneck, not orchestration
Most teams can now assemble an agent harness: tool calling, retries, monitoring, guardrails, basic evaluation. All of that is necessary, but it is not sufficient. The hard part is codifying scientific workflows at the right level of granularity. “Target nomination,” “candidate selection,” “protocol drafting,” and “safety signal triage” are not single problems but composites of dozens of micro-decisions, each with its own evidence requirements, failure modes, and organizational conventions. If you can’t decompose the workflow into constituent steps that are:
- specific enough for an agent to follow,
- constrained enough to be testable,
- and explicit about what evidence qualifies as “done,”
then the harness will simply execute a vague plan more efficiently and you’ll still be stuck with outputs that drift, can’t be reviewed systematically, and don’t scale across teams.
2) You need partners who are fluent in scientific work, not just enterprise delivery
Productionizing R&D use cases requires a partner that can sit with a translational lead, a clinical scientist, a biostatistician, and an informatics team and accurately translate real scientific workflows into an executable specification. That demands deep familiarity with:
- how evidence is generated and weighted in biomedical decisions,
- which internal and external sources are authoritative for which sub-decisions,
- how review gates operate in practice,
- and where provenance, traceability, and reproducibility are non-negotiable.
This is where companies built specifically for scientific R&D have an inherent advantage: the combination of (i) scientific-grade information retrieval and evidence stitching, (ii) an agentic execution layer, and (iii) detailed workflow understanding that can be codified into repeatable steps.
The upside: scientists become architects, not human glue
A useful mental model is what’s happening in software engineering with agentic development. Senior/staff engineers are not typing faster - they’re directing, setting intent, defining constraints, reviewing diffs, and steering architecture while agents do large volumes of implementation work.
The R&D analog is powerful: scientists spend more time on hypothesis, tradeoffs, and decision quality—while agents execute the repeatable investigative steps, assemble evidence, and draft structured artifacts for review. That shift is the real prize of Phase 2: AI that reliably executes workflows, under human control, with outputs that an organization can trust. 2026 will be an unusually dynamic year for life sciences organizations adopting AI. The leaders who win will be the ones who treat agentification as workflow engineering: rigorous decomposition, explicit contracts, and partners who understand the scientific substrate deeply enough to make automation real.
Further reading

.png)

.png)
.png)


.png)

Get started with Causaly
Ready to transform the way your R&D teams discover and deliver? Take the first step - see Causaly for yourself.
Request a demo