The Agent Harness That Makes Scientific AI Work
In biopharma R&D, the model alone does not determine whether a system is useful, trusted, or deployable inside a scientific workflow. The decisive layer is the harness around the model
.png)
A common reaction I hear in conversations about agentic AI is that models are becoming interchangeable, and that the application layer will therefore matter less over time. I understand why people say this. Frontier models are improving quickly. They are getting better at reasoning, tool use, coding, and long-context synthesis.
.png)
In many domains, that progress is enough to make the interface or workflow around the model feel secondary. But in scientific R&D, that conclusion is wrong.
The model matters. It would be incorrect to pretend otherwise. Different models have different strengths in reasoning, latency, multimodal performance, tool use, and cost. Those differences can affect real product behavior.
But in biopharma R&D, the model alone does not determine whether a system is useful, trusted, or deployable inside a scientific workflow.
The decisive layer is the harness around the model: the structure that determines what evidence it sees, how it operates, what it is allowed to do, how it is evaluated, and what kind of output it must produce.
That harness is where the product lives.
This becomes obvious the moment you move beyond a demo. A frontier model can generate a plausible answer to a scientific question. It can summarize a paper, draft a short rationale, or produce a coherent paragraph about a target or mechanism.
But scientific organizations do not run on plausible paragraphs. They run on workflows that require evidence, review, traceability, reproducibility, and outputs that fit into a real process.
A target assessment is not a single question.
A safety triage is not a prompt.
An indication expansion analysis is not a chat exchange.
These are structured pieces of work with implicit standards for completeness, evidence quality, and decision usefulness.
If you want AI to support them reliably, the system needs more than a strong model. It needs an execution harness that can translate model intelligence into scientific work.

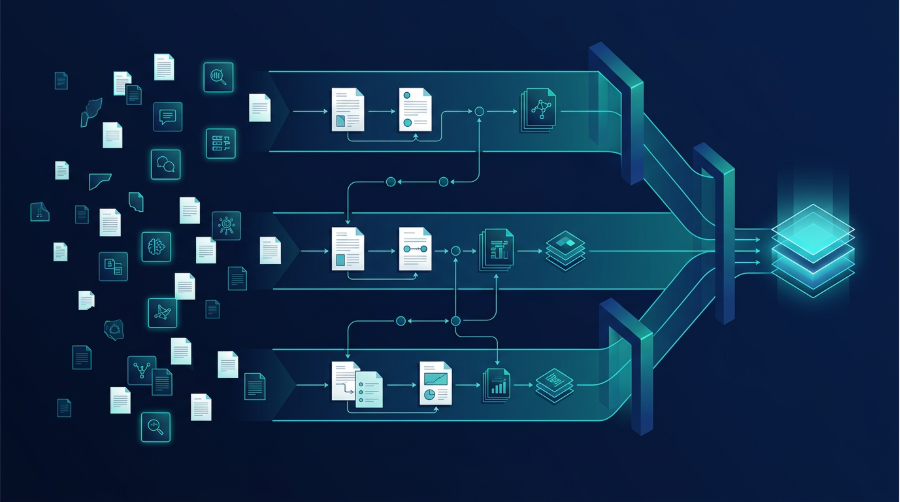
The harness that makes scientific AI usable has five core components: retrieval, workflow structure, provenance, context, and evaluation.
Retrieval
The harness starts with retrieval. Scientific reasoning is only as good as the evidence brought into the context window. In life sciences, decisive information is often buried in methods sections, supplementary figures, toxicology tables, internal reports, and private PDFs.
A model that receives the wrong evidence does not fail gracefully. It fills gaps with language. That is why retrieval in R&D has to be treated as a first-class capability: full-text coverage, page-level anchoring, entity normalization, and ranking tuned for scientific signal rather than generic relevance.
Workflow Structure
The second part of the harness is the workflow structure. A production workflow is not a prompt with some guardrails around it. It is closer to an executable SOP. The system needs a defined sequence of steps, clear evidence dimensions, intermediate artifacts, stop conditions, and a contract for what the output must look like. If a target assessment requires specific sections, evidence tables, assumptions, and limitations, then those are not optional formatting choices. They are part of the work itself.
This is where many conversations about agents become too abstract. Teams focus on whether a model can use tools, plan, or run for multiple steps. Those capabilities are necessary, but they are not the bottleneck. The harder problem is decomposing scientific workflows into units that are specific enough to execute, constrained enough to test, and explicit enough to evaluate. Without that decomposition, the harness simply helps the model execute a vague plan more efficiently, and the result remains difficult to rely on.
Provenance
The third part of the harness is provenance. In science, an uncited answer is not merely incomplete. It is operationally weak. Scientists need to know which evidence supports a claim, where conflicting evidence exists, and how a conclusion was formed.
The right output is therefore not only a narrative. It is a package of artifacts: citations, evidence tables, assumption logs, limitations, and traceable reasoning steps that can be reviewed by another expert.
Context
The fourth part is context. The same workflow should behave differently depending on the role of the user, the risk posture of the organization, the internal data available, and the decision being supported.
A translational scientist, a safety physician, and a portfolio lead may all ask about the same target, yet require different emphases, different evidence weighting, and different thresholds for sufficiency.
The harness is what makes that context operational. It determines which sources are authoritative, which tools are permitted, which criteria define “done,” and how conservative the system should be in each setting.
Evaluation
The fifth part is evaluation. In enterprise R&D, quality cannot be inferred from how polished an answer sounds. It must be measured.
That means evaluating retrieval quality, evidence coverage, provenance completeness, reasoning structure, artifact quality, and reproducibility. It also means making scientific judgment explicit: what counts as a strong output for target assessment is different from what counts as sufficient support for a regulatory brief or a governance pack. The harness is where those standards are encoded and enforced.
This is also why the language of “model commoditization” is too simplistic for life sciences. Even if frontier models converge on general capabilities, the harness remains highly differentiated because it reflects domain knowledge, workflow understanding, product design, and the user’s operational reality.
Two companies may use similarly capable models and still deliver very different systems. One will generate impressive text. The other will produce a governed scientific artifact that a team can actually use.
That distinction matters more with every improvement in the model layer, not less.
The enduring value in scientific AI will not come from wrapping a model with a chat interface and hoping the model is smart enough to compensate for missing structure. It will come from building systems that know how to retrieve the right evidence, execute the right workflow, produce the right artifact, expose the right provenance, and stop at the right point under the right controls.
In biopharma R&D, that is the difference between a model that looks impressive and a product that becomes infrastructure.
Further reading






.png)
.png)

Get started with Causaly
Ready to transform the way your R&D teams discover and deliver? Take the first step - see Causaly for yourself.
Request a demo