What Does It Take to Find the Right Target?
Dr. Siddhartha Mukherjee, co-founder of Manas AI, on why every decision in drug development flows from a single first question, and how AI is changing the quality of the answer.
.jpg)
Drug discovery is a process of compounding commitment, in which every step forward, from laboratory hypothesis to phase three trial, amplifies whatever judgment preceded it, so that an error at the outset propagates through the entire program and cannot be contained at the stage where it originated.
That first step is target selection, and it is the subject that Dr. Siddhartha Mukherjee returns to most insistently. A Pulitzer Prize-winning author, oncologist, and cancer biologist at Columbia University, Mukherjee co-founded Manas AI to build an end-to-end AI-native platform for drug development, and the question at its center is whether the biological target is causally responsible for the disease.
The End-to-End Problem
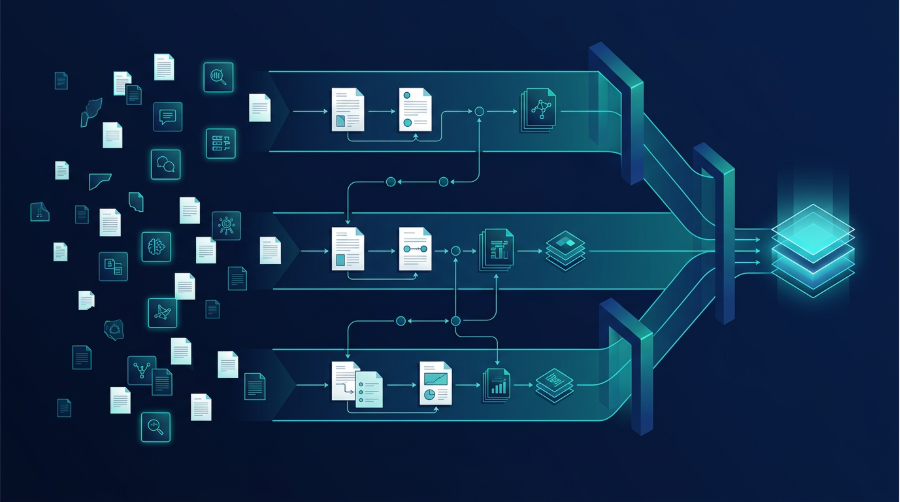
Mukherjee's argument for AI in drug development begins with a structural observation about the industry's current model. Pharmaceutical and biotech companies spend years building toward a single product, and when it fails, which most candidates do, the cost of that failure has been distributed across every stage of the pipeline. The throughput constraint, in his view, is what breaks the model, because the industry needs far more viable candidate molecules than existing manual processes can generate.
Manas AI is building what Mukherjee describes as a foundation model for drug development, one that operates across each stage of discovery as an integrated system, so that evidence, predictions, and optimization signals flow forward through the pipeline without being re-derived at each step.
1. Target Identification
Determine whether the protein or signaling complex is causally implicated in disease, drawing on human genetics, preclinical data, and clinical trial results.
2. Pocket Identification
Locate the structural site where a molecule can bind. Proteins are dynamic, so viable pockets can be cryptic, appearing only when the protein moves.
3. Molecule Design
Generate candidate molecules through "build and grow," where an AI constructs a molecule shaped to the pocket's geometry, avoiding the combinatorial intractability of searching a finite virtual library against an effectively infinite chemical space.
4. Optimization and ADMET
Evaluate whether the candidate can be synthesized, reaches the right tissue, survives metabolic processing, and avoids toxicity, since these properties determine whether a molecule can function as a drug.
5. Clinical Translation
AI agents support trial submission, data analysis, and the feedback of clinical signals back into earlier stages of the pipeline.
Each stage, Mukherjee notes, involves a qualitatively different kind of reasoning, and his analogy is instructive. A skilled medicinal chemist can look at a proposed molecule and assess in seconds whether it will function as a drug, drawing on years of accumulated intuition about chemistry, physics, and biology simultaneously, and that kind of multi-domain, experiential judgment is precisely what AI systems are being trained to replicate.
Target Evidence at the Speed of an Agent
Target selection demands a particular kind of evidence synthesis. To evaluate whether a biological target is causally implicated in a disease, researchers need to integrate findings across human genetics, animal model studies, clinical trial outcomes, competitor activity, and recorded adverse effects, bodies of evidence that span thousands of papers, written in different scientific traditions and assessed against different standards of rigor.
Mukherjee describes the pre-AI version of this work as resembling the parable of the blind men and the elephant, where each researcher touches a different piece of the evidence base and forms a partial impression of the whole. The architecture of the process, not the quality of individual researchers, produces the gap, because no team working manually can hold all the relevant evidence in view at once.
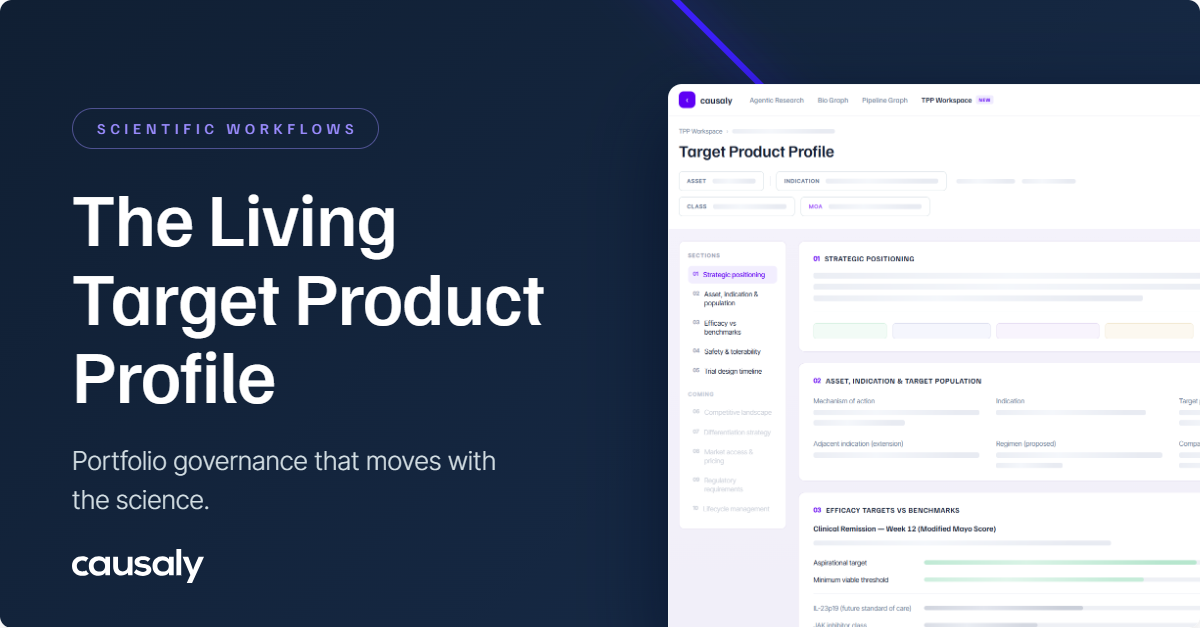
For Manas, using Causaly means that a single target assessment produces a structured, navigable synthesis of the evidence, including the depth of preclinical data, the strength of genetic support, how many competitors have investigated the same target, what they found, and what adverse effects have accumulated. The researchers reviewing that output still make the judgment; what changes is how much of the available evidence they can bring to that judgment, and how long it takes to surface it.
Why Validity Is Established in the Physical World
Mukherjee's distinction between AI as a replacement and AI as a collaborator reflects something specific about where the process breaks down when AI acts alone, not as a rhetorical position but as a description of how computational prediction relates to physical validation.
His preferred term is augmented intelligence. At every stage of drug development there is a transition from information, from computational prediction and data synthesis, to physical reality, from synthesized molecules and biological experiments to human trials. No computational system, however sophisticated, can close that transition unilaterally, because the validity of a proposed medicine is established in the physical world, not in silico, and AI's role is to make the human judgment at that transition point as well-supported as the available evidence allows.
He extends the point to the question of autonomous, end-to-end AI pipelines. In principle, a sufficiently capable AI could coordinate each stage of drug development the way a human coordinates the distinct cognitive tasks involved in getting through a morning, where the reason humans manage that coordination is not that each task is simple, but that an overarching operating system sequences and monitors each step.
Current AI systems can perform individual steps with considerable sophistication, but the coordination layer that ensures the output of one stage is fit for the next still depends on human oversight. At Manas, that means checking target identification outputs against Causaly's evidence synthesis before moving to pocket identification, validating pocket structures against crystal data, and asking computational chemists to review AI-generated molecule proposals.
New Classes of Medicine
Mukherjee's longer-horizon claim is that AI-native discovery will generate categories of medicine that are difficult to design through conventional approaches, beyond accelerating the production of existing drug types.
The example he gives at Manas is conjugated therapeutics, molecules that combine an antibody with an RNA, where the antibody directs the payload to the correct cell type and the RNA carries out the biological intervention. Combinations of lipids and RNA are already approved medicines, in which the lipid particle delivers the RNA to the liver, where it modulates a pathway implicated in disease. The design logic is rooted in biology, but the precision required to engineer the construct and to optimize the molecular properties of each component simultaneously represents an order of complexity where AI determines whether the problem is tractable.
The principle Mukherjee returns to is that AI amplifies science by providing the computational reach to act on well-validated biology at a scale and speed that manual methods cannot match.
Explore how Causaly's evidence synthesis agents support target assessment workflows across therapeutic areas, and see how pharmaceutical research teams are using structured literature retrieval to validate biological hypotheses before committing resources to the next stage of discovery.
Further reading






.png)
.png)

Get started with Causaly
Ready to transform the way your R&D teams discover and deliver? Take the first step - see Causaly for yourself.
Request a demo