Context Graphs: A Prerequisite for Agentic AI in Enterprises
If you want reliability, reproducibility, and sustained adoption, context must be treated as a first-class product layer rather than an afterthought.
.png)
A common translational challenge most R&D organizations encounter is when a preclinical package shows an emerging safety signal for a novel immunology mechanism, requiring the project team to decide what to do next. The immediate ask is often: “Triage the signal and propose next experiments.” A good scientist can understand that sentence because they know the context of what "triage" means in their organization.
Now imagine giving an AI system only the surface request. You type exactly what you would tell a colleague: “Triage this safety signal and propose next experiments.” That prompt sounds complete because it matches the human objective, but for a model it is underspecified. The system has to guess which of the above rules applies. These guesses affect everything downstream which evidence it retrieves, which hypotheses it prioritizes, and which experiments it recommends.
Humans avoid this failure mode because they interpret intent through two lenses at once: personal context (who is asking, what they are responsible for, what they have already tried, how they decide) and organizational context (portfolio reality, mechanism footprint, risk posture, and what has changed recently). An agentic AI system needs those same lenses made explicit, so it can interpret intent consistently and behave predictably.
Implicit knowledge and commonly omitted context in the prompt
- Program intent and timing: whether this is exploratory work or tied to an IND-enabling decision with a fixed window.
- Indication-specific risk posture: the patient population, baseline risk, and which liabilities are unacceptable for the franchise.
- Mechanism and class history: whether adjacent mechanisms have known liabilities, and what the organization has learned before.
- Internal standards and playbooks: which assays, species, and endpoints the organization trusts, and what constitutes a gating result.
- Decision constraints: what must be answered to move forward, what can wait, and what would trigger a stop.
Agentic AI and enterprise context
Agentic AI becomes reliable in an enterprise when intent is consistently interpreted, decisions can be traced back to evidence, and results can be reproduced across users and time. That reliability depends on context that persists beyond a single chat thread. The most practical representation of that context is a context graph: a structured, time-aware model of user and enterprise context with explicit provenance and update logic.
Context has two halves: the personal and organizational. This becomes clear when the same request encodes different intent depending on who asks it. Take a prompt like “Propose a viable target for lupus.”
- Translational physician scientist: expects human genetics support, biomarker strategy, patient stratification logic, and an early view on safety liabilities and clinical plausibility.
- Computational biologist/systems biologist: expects pathway-level coherence, cell-type context, perturbation signatures, and a hypothesis for validating causality in relevant models.
- Clinical development leader: expects precedent awareness, endpoint and population implications, competitor landscape signals, and what regulators tend to scrutinize for that mechanism class.
A system that treats the prompt as self-contained is forced to guess which of these intents applies. In an enterprise, guessing is expensive because it generates plausible output that is misaligned with the decision the user is trying to make.

Personal context: what the system should remember about the scientist
A straightforward way to make personal context concrete is to imagine a scientist returning to a problem after a few weeks. They do not start from zero. They remember what they already searched, which hypotheses they discarded, which datasets they trusted, and what the team concluded. They also remember the working constraints: whether this is a quick meeting prep or a multi-week target nomination effort.
A useful system carries forward the same continuity. Practically, personal context consists of two complementary memory types.
1) A record of what happened across time
This includes searches, questions asked, reports generated, alerts set, and artifacts saved. It helps the system avoid repeating work, suggests reuse, and determines whether a request continues with a prior thread or starts a new one. This is often called episodic memory, because it captures a sequence of events.
2) A stable profile of who the user is and what persists
Role, department, and durable scientific orientation shape what “good” looks like. A translational user prioritizes human evidence and biomarker feasibility; a safety lead focuses on class effects and label anchoring; a computational user emphasizes model systems and causal graphs. This is often called semantic memory, because it represents stable attributes and durable facts rather than a timeline.
Semantic memory can also include derived elements, such as topic affinities inferred from repeated work. Those elements benefit from time-awareness because the research focus shifts. A system can treat them as “recently relevant” rather than a permanent identity.
With personal context organized into these two layers, the system can do something operationally important: interpret intent without requiring the user to restate their role and recent work at the start of every interaction.
Organizational context: what the system should know about the enterprise
In biopharma, a minimal set of organizational context that materially improves decision support includes:
- Therapeutic and mechanism footprint: what disease areas and mechanism classes are central to the company’s portfolio and experience base.
- In-market coverage and liabilities: where the company already carries safety posture and regulatory exposure for certain classes.
- Pipeline shape at the portfolio level: modality mix, active indication coverage, and a stage distribution that reflects how late-stage commitments influence decision-making.
- Time-indexed events: approvals, label changes, pivotal readouts, major BD moves, and manufacturing investments that shift priorities and constraints.
.png)
This context can be bootstrapped effectively from public sources: annual reports, investor presentations, pipeline disclosures, regulatory labels, trial registries, patents, and publications. Internal enterprise data can deepen it over time, including internal documents, operating models, and directory information. The key point for deployment is that a meaningful baseline can be created without waiting for integrations and then improved incrementally.
Why represent context as a graph
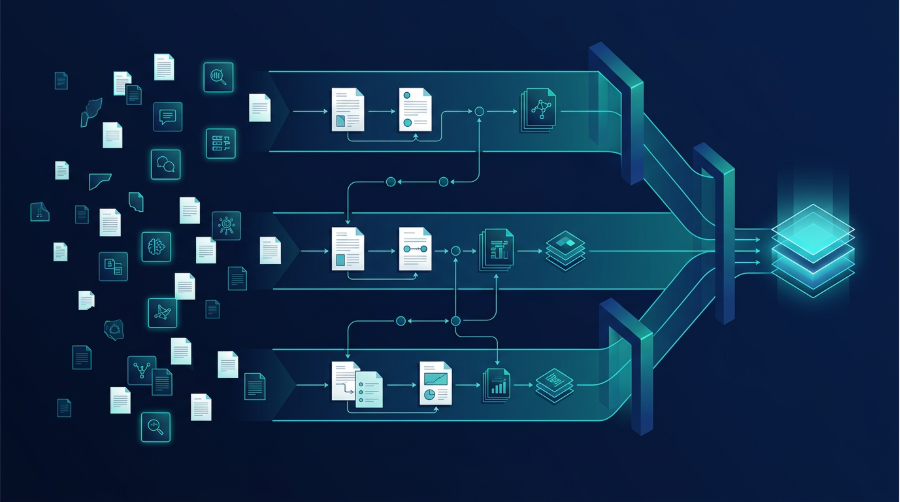
A graph enables an important feature for agentic systems: selective context use. The system should not inject every known fact into every interaction. Instead, it should supply a compact, relevant subset and retrieve deeper, detailed nodes only when evidence or specificity is required. In practice, that means:
- Keeping the full context graph in storage, with timestamps and sources.
- Maintaining a small “injection view” that is optimized for model consumption (portfolio summaries, current coverage maps, recent changes).
- Retrieving deeper detail on demand when a question requires specificity, citations, or auditability.
This approach mirrors how we think about graphs in biopharma R&D. Biological reasoning benefits from explicit, navigable structures, whether you are modeling causal relationships in a Bio Graph or mapping development activity in a Pipeline Graph. A context graph plays the same role for the user and the enterprise: it makes assumptions explicit, keeps them updatable, and anchors reasoning to a stable substrate.
Implications for Day-to-Day Enterprise AI Operations
When personal and organizational context are represented explicitly and carried across sessions, three things become true.
- First, intent becomes interpretable. The system can distinguish between meeting prep and a gated decision, between exploration and validation, and between a mechanistic question and a portfolio question.
- Second, behavior becomes predictable. Agentic workflows can choose tools, retrieval targets, and consistently structure outputs because they start from consistent assumptions.
- Third, outputs become reproducible. When a system has persistent context and clear provenance, teams can rerun workflows and understand why a result was produced, even if the underlying evidence evolved.
For CIOs and R&D leaders, this is the dividing line between systems that demo well and systems that become infrastructure. The model matters, the product's surface matters, and context is what binds them into something an enterprise can rely on.
A context graph is the most practical way to make user intent legible to the system, updatable over time, and compact enough to use selectively. If you want reliability, reproducibility, and sustained adoption, context must be treated as a first-class product layer rather than an afterthought.
Further reading






.png)
.png)

Get started with Causaly
Ready to transform the way your R&D teams discover and deliver? Take the first step - see Causaly for yourself.
Request a demo