Moving Beyond AI Answers to How Science Actually Gets Done
Life sciences R&D has never lacked information. What it has always lacked is a reliable way to turn that information into decisions the whole organization can stand behind.
.png)
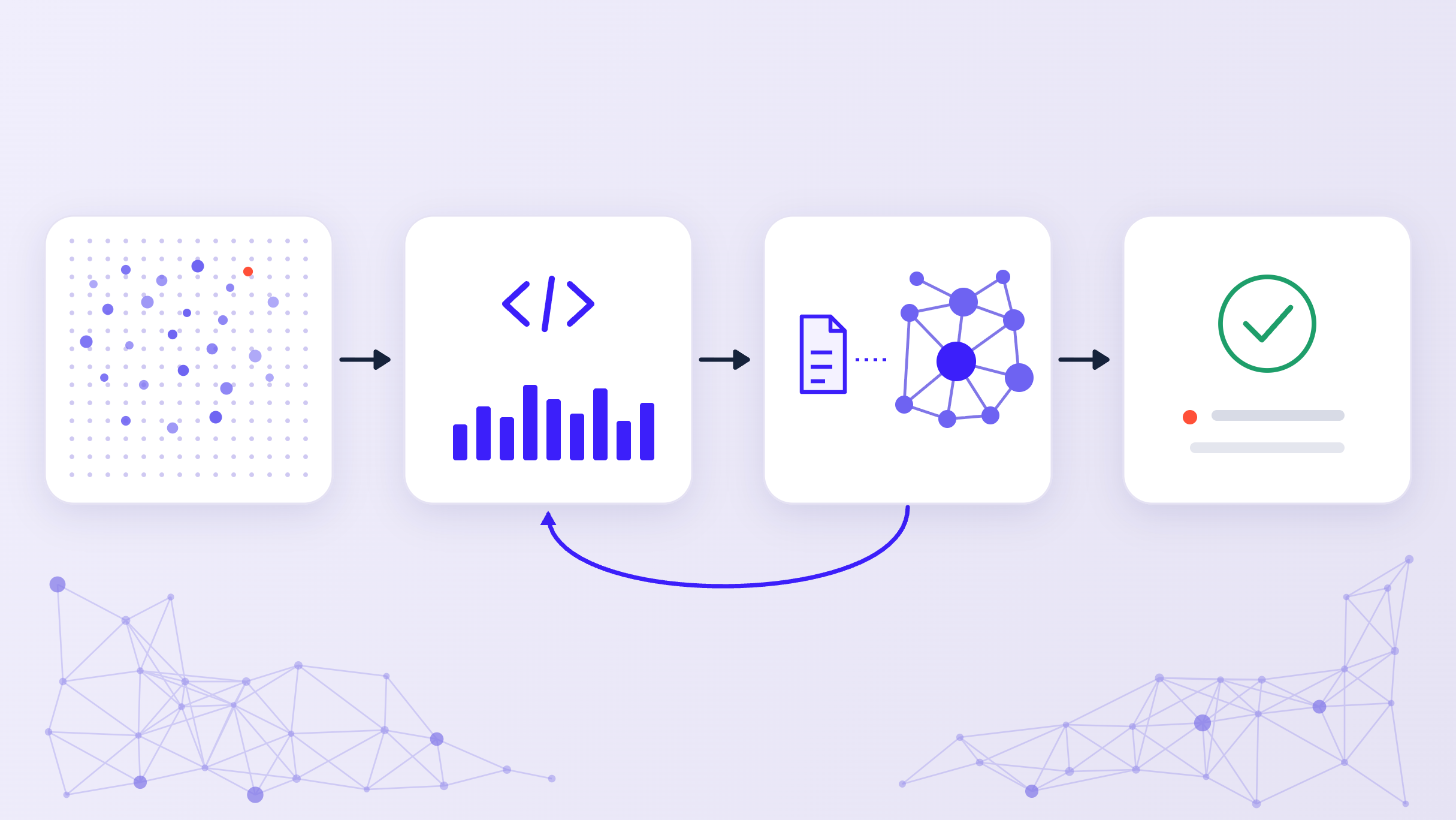
Most R&D teams have now been through at least one AI pilot. The tool retrieves well. The summaries are accurate. The interface is clean. And then the pilot ends, and the work goes back to being done the way it was always done.
The reason is rarely the quality of the answers the tool produced. The reason is that better answers, on their own, do not change how scientific work gets done. They sit alongside existing processes rather than inside them. They produce outputs that live in a chat interface rather than in the places where decisions get made. They have no memory of what the team worked on before, and no connection to the proprietary data and prior analyses that make an organization's knowledge distinct.
After enough of these experiences, a reasonable skepticism sets in. Not towards what the technology can do in a demonstration, but towards whether it will ever change anything that matters. This is the reality of AI fatigue in life sciences R&D.
The Gap in Life Sciences AI Adoption
The tools that have struggled to stick share a common design assumption: that the value of scientific software is in the answer it produces, and that getting to the answer faster is sufficient.
For individual scientists doing exploratory work, that may be the case. For organizations making high-stakes decisions consistently, with multiple stakeholders, governance requirements, and institutional knowledge that needs to survive beyond any individual project, it falls short.
The gap shows up in predictable ways. Like analyses done differently by different people working on the same question. Findings that live in one scientist's notes and go nowhere when they move to another project. Decisions that cannot be reconstructed months later when someone asks how the conclusion was reached. Knowledge that resets with every new project rather than building into something the organization can draw on over time.
A Principal Scientist at a top-ten pharma company described it plainly: "For the 40 targets we shortlisted, we're sending them to individual biologists for a deep dive. Everyone is doing it differently. It's a lot of manual work."
This is not a problem that faster retrieval solves. The evidence exists. The scientists are capable. The challenge is the process that sits between finding information and making a decision. This is where AI adoption fails in life sciences.
Defining the Objective of AI in R&D
It helps to be precise about what the actual goal is.
If the goal is faster access to scientific literature and cleaner summaries, the options are broad, and the differences between them are narrowing. General-purpose models have closed much of that gap and will continue to do so.
If the goal is to change how R&D decisions get made inside a real organization, to make them more consistent, more traceable, and less dependent on individual effort and institutional memory, then the requirements are different. The software needs to reflect how a specific organization approaches a specific type of problem. It needs to connect to that organization's own data and prior work. It needs to produce outputs that hold up under the scrutiny of regulators and senior stakeholders, with full traceability of the scientific evidence.
Those two goals call for fundamentally different things.

Reproducibility Is a Process, Not an Outcome
In research, reproducibility is a baseline condition for trust. A finding that cannot be reproduced is not a finding. The same principle applies to the processes through which scientific decisions get made.
A target prioritization carried out differently by ten different biologists is not a process. The variability is not a sign of scientific rigour. It is a sign that the organisation has not yet encoded how that decision should be made.
The tools that change this are built around R&D workflow automation rather than retrieval. Workflows that reflect how a specific organization approaches a specific type of decision. Workflows where every step is visible, every source is traceable, and the output is structured enough to be stored, shared, and built upon. Where a scientist, running the same process months later, starts with the organizational context rather than from scratch.
It is where durable value accumulates. Not in any individual answer the software produces, but in the structured, reusable, auditable work that builds over time into something the whole organization can rely on.
Measuring the Right Outcome
The right benchmark for scientific process governance in life sciences is not whether it can find a good answer. Most tools can produce a reasonable answer to most questions.
The benchmark is whether the organization using it makes better decisions more consistently, with less manual coordination overhead and a clearer record of how those decisions were reached. It is whether a team using it a year from now is faster, more consistent, and better able to demonstrate the reasoning behind its conclusions than a team that is not. That is scientific workflow consistency in R&D
That is a harder standard. It also happens to be the one worth measuring against.
Further reading

.png)

.png)
.png)


.png)

Get started with Causaly
Ready to transform the way your R&D teams discover and deliver? Take the first step - see Causaly for yourself.
Request a demo