The FDA’s New Guiding Principles for AI in Drug Development
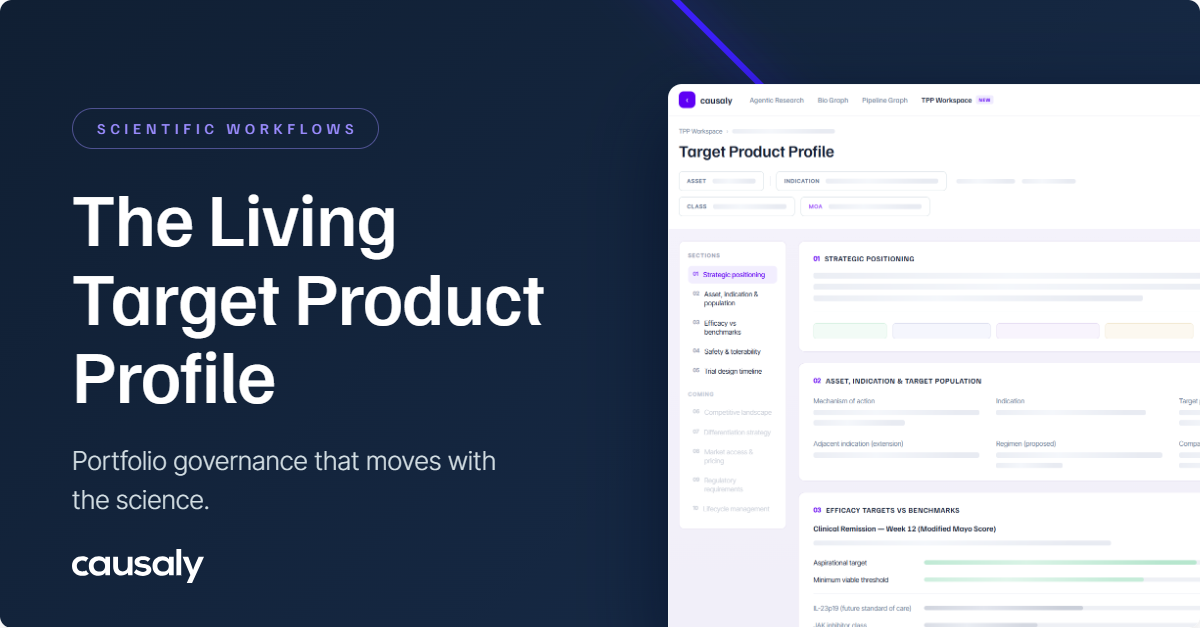
Causaly has been building toward this standard long before it was formalized, by designing Agentic Research that reasons within a scientific context, generates evidence-centric outputs, and supports accountability by design.
.png)
“As the use of AI in drug development evolves, so too must good practice and consensus standards.”
Earlier this month, the FDA released its Guiding Principles of Good AI Practice in Drug Development. It defines expectations for how AI systems must behave today, particularly when they generate evidence or inform decisions that affect patient safety, regulatory approval, and scientific credibility. This emphasizes that AI is no longer assessed primarily on performance or productivity. It is assessed on credibility.
From Capability to Accountability
The FDA acknowledges AI’s growing role across pre-clinical, clinical, post-marketing, and manufacturing settings. But that acknowledgment comes with a condition:
“As new technologies emerge, including AI, it is essential that their use reinforces these requirements for the benefit and safety of patients.”
The question is no longer what AI can do, but whether its outputs can be trusted. The guidance’s first principle makes this explicit:
“The development and use of AI technologies should follow a risk-based approach with proportionate validation, risk mitigation, and oversight based on the context of use and determined model risk.”
This reflects a core scientific reality: results cannot be evaluated in isolation. Credibility of AI output depends on context, provenance, and appropriate oversight. Once AI systems begin influencing scientific decisions, accountability becomes structural.
What the Guidance Implies for AI Design
Much of today’s AI tooling in R&D has been built around conversational interaction, copilots that summarize, retrieve, or generate fluent responses. These tools are useful, but they were not designed to meet regulatory standards for evidence generation.
The FDA’s principles emphasize documentation, interpretability, traceability, and lifecycle governance. These are not attributes of language interfaces; they are properties of systems.
Implicit in the guidance is a shift toward AI that performs defined scientific tasks, produces structured outputs, and can be reviewed and audited - what Causaly refers to as agentic workflows. This raises a fundamental design question: how do AI systems reason within science, rather than simply talk about it?
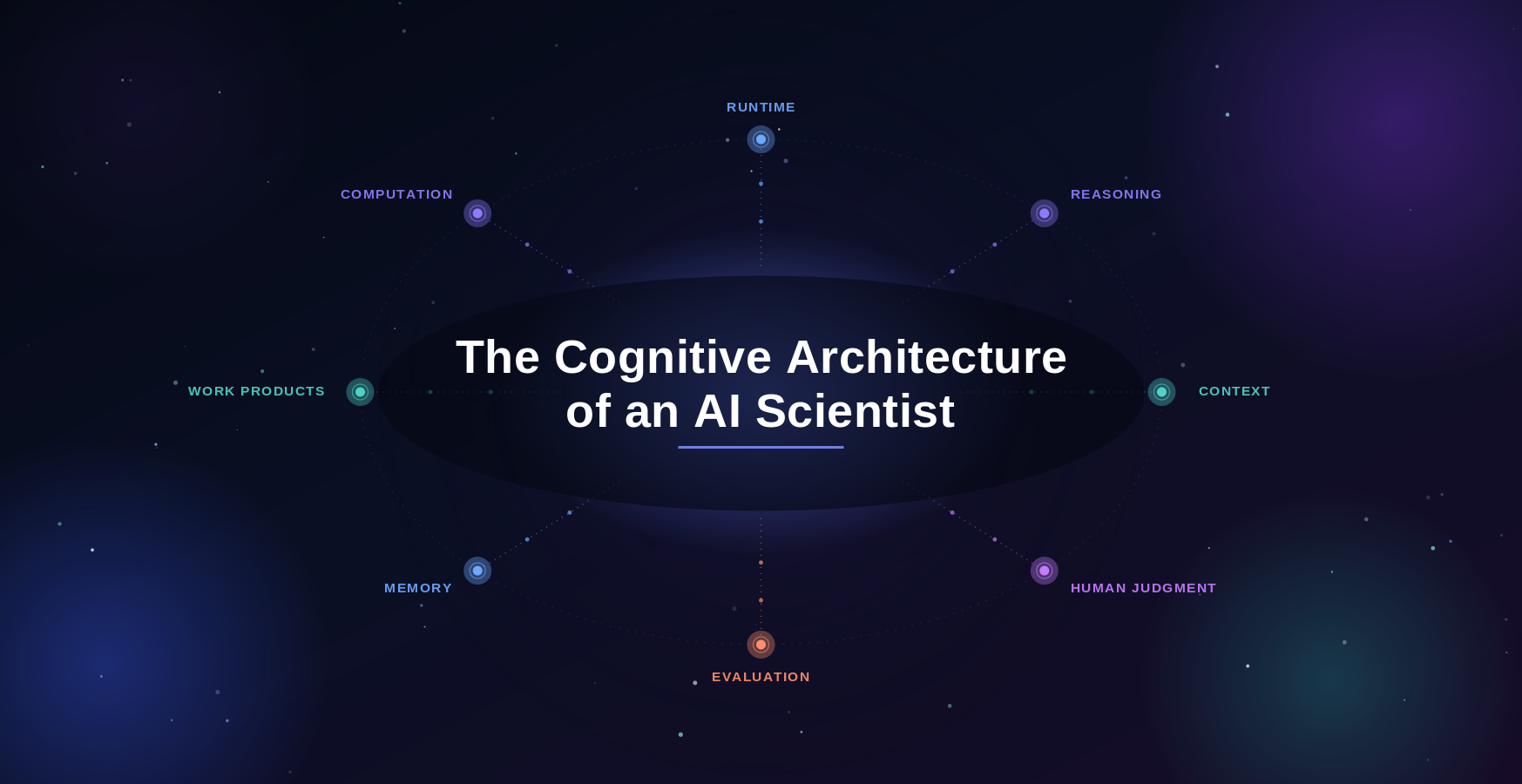
Context as a First-Class Requirement
The FDA repeatedly stresses the importance of context of use. But context is not metadata that can be appended after the fact. It must be embedded in the system’s reasoning.
Causaly addresses this through Context Graphs, which represent domain knowledge in a structured, machine-reasoning-ready form. Context Graphs encode:
- Scientific entities (e.g. genes, pathways, phenotypes)
- Explicit relationships (causal, associative, hierarchical)
- Evidence provenance and certainty
- Domain constraints that limit inappropriate inference
This structure ensures that Causaly’s AI outputs are generated within a defined scientific frame. Claims are grounded in evidence, reasoning is constrained by domain logic, and conclusions are traceable. These characteristics map directly to the FDA’s expectations for interpretability, traceability, and risk-aware application.
Good AI Practice Is Structural, Not Conversational
Throughout the guidance, the FDA emphasizes that AI systems generating evidence must support detailed documentation and auditability:
“Data source provenance, processing steps, and analytical decisions are documented in a detailed, traceable, and verifiable manner, in line with Good Practices (GxP) requirements.”
An agentic system built on Context Graphs produces outputs with exactly these properties:
- Provenance: Every claim links back to source evidence
- Structure: Reasoning follows explicit, graph-based logic
- Verifiability: Outputs can be retraced and interrogated
This is the difference between AI as an assistant, and AI as part of the scientific record.
Evaluating AI with Regulatory Guidance
The FDA makes clear that performance assessment cannot focus on the AI model alone. When AI is used to generate or support scientific evidence, evaluation must consider the complete system, including how outputs are reviewed and acted upon in practice:
“Risk-based performance assessments evaluate the complete system including human–AI interactions.”
Causaly’s approach is explicitly human-in-the-loop. AI outputs are not treated as conclusions, but as draft scientific analyses that are reviewed, challenged, and ultimately owned by human experts within regulated workflows. The role of the system is to structure evidence and reasoning in a way that makes expert review possible and reliable at scale.
In this context, “human–AI interaction” does not mean free-form dialogue. It means that AI outputs must be produced in a form that allows human reviewers to verify claims, interrogate reasoning, assess uncertainty, and determine fitness for use within a defined context.
In practical terms, this means AI systems must be evaluated based on whether their outputs can be systematically reviewed, challenged, and contextualized within a scientific workflow. To do that consistently, those outputs must be assessed against explicit criteria that reflect how scientific evidence is evaluated in regulated science.
Causaly applies a 5-Dimensional Benchmark (the 5Ds) to operationalise this evaluation:
- Factuality ensures that human reviewers can independently verify claims against primary evidence.
- Depth of Analysis reflects whether the system’s reasoning meets the level of scientific interpretation expected by domain experts.
- Argument Structure determines whether reviewers can follow and interrogate the logical path from evidence to conclusion.
- Assumption Transparency makes underlying hypotheses visible so reviewers can assess their validity.
- Limitation Disclosure ensures uncertainty and scope are explicit, supporting responsible expert judgment.
Together, the 5Ds assess whether an AI system produces outputs that genuinely support human-in-the-loop scientific decision-making. They do not measure model performance in isolation; they evaluate whether the system enables human experts to remain accountable for decisions informed by AI.
What the FDA Guidance Ultimately Signals
The FDA’s Guiding Principles point to a clear standard: AI used in drug development must generate reviewable, evidence-centric outputs with explicit context, provenance, and transparent reasoning.
This standard is achievable only when:
- Domain knowledge is represented explicitly
- Reasoning is structured and constrained
- Outputs are designed to be audited
- Human oversight is built into the system
The guidance states:
“Clear, accessible, and contextually relevant information should be provided regarding the AI technology’s context of use, performance, limitations, underlying data, and interpretability.”
This is precisely the design principle of Causaly’s platform.
Why This Matters Now
The FDA’s guidance is not an isolated policy document. It reflects a broader convergence between regulatory expectation and scientific best practice. AI that influences scientific decisions must behave like scientists.
That means explicit knowledge representation, structured reasoning, visible assumptions and limitations, and verifiable outputs. Good AI practice is no longer theoretical. It is becoming policy.
Causaly has been building toward this standard long before it was formalized, by designing Agentic Research that reasons within a scientific context, generates evidence-centric outputs, and supports accountability by design.
Further reading






.png)

Get started with Causaly
Ready to transform the way your R&D teams discover and deliver? Take the first step - see Causaly for yourself.
Request a demo