The 5 Dimensions of Trustworthy Agentic AI in Scientific R&D
Scientific decisions depend on accurate interpretation of evidence and rigorous reasoning across studies. A single unsupported claim or misinterpreted citation can misdirect entire lines of investigation. Trust, therefore, depends on whether an AI system faithfully interprets and represents the available evidence.

Operationalizing AI products has moved beyond just the frontier of innovation or competitive advantage. It is becoming table stakes across the life sciences industry. Over the last six months, the AI market has entered a new phase of maturity. Organizations are shifting from asking whether AI can generate answers to whether those answers can be trusted to support real work.
In life sciences, where drug development programs span more than a decade and require billions of dollars in investment, the stakes are unusually high.
Scientific decisions depend on accurate interpretation of evidence and rigorous reasoning across studies. A single unsupported claim or misinterpreted citation can misdirect entire lines of investigation. Trust, therefore, depends on whether an AI system faithfully interprets and represents the available evidence.
Despite these factors, most AI benchmarks remain rooted in an earlier phase of the technology. They measure baseline capabilities such as retrieval accuracy or reading comprehension, but do not assess whether an AI system can construct a viable scientific argument or produce reliable results. Thus, a gap has emerged between how AI systems are evaluated and how they are used.
Instead of evaluating AI systems like search engines or chat interfaces, what would it look like to evaluate them like scientific collaborators?
Scientists do not rely on a single metric for evaluation. A range of factors have an outsized impact on the value of scientific progress - including how trustworthy, traceable, and well-considered evidence is, how well logical reasoning is presented, and how transparent work is overall. Instead, they assess research across multiple criteria that reflect how scientific work is conducted.
To capture these criteria, Causaly has developed an evaluation framework across five key dimensions. The framework evaluates AI-generated scientific results against the rigorous standards that science demands.
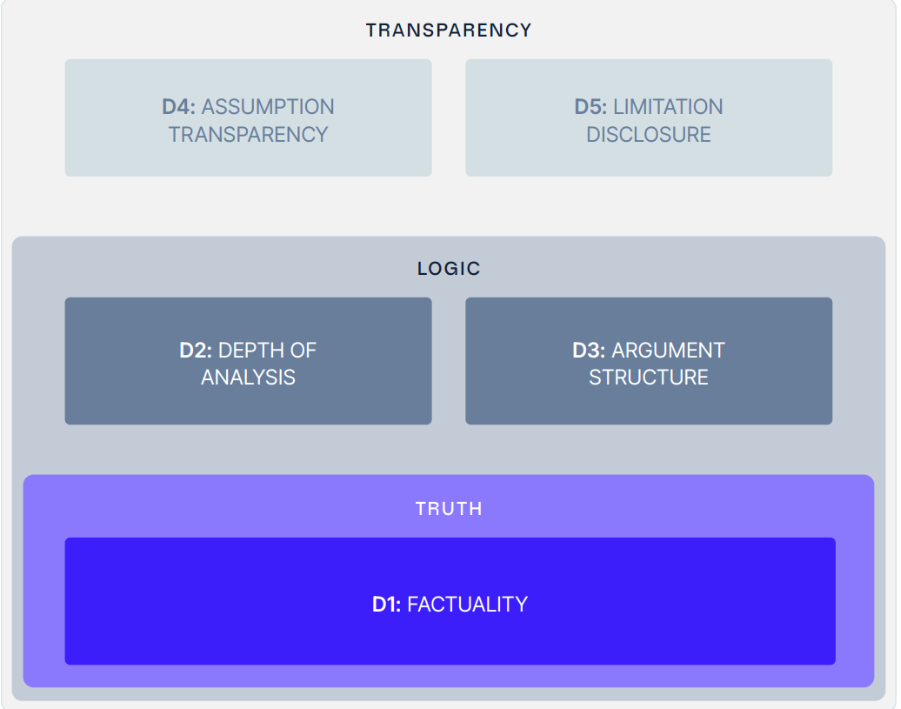
Rather than measuring whether a model retrieves the correct sentence from a paper, the 5 Dimensions evaluate whether it can transform evidence into a credible scientific argument.
The Five Dimensions of Scientific AI Evaluation
The 5-D framework evaluates AI across five complementary dimensions. Each dimension captures a different aspect of how scientific reasoning is expressed in research reports.
1. Factuality
Scientific reasoning begins with accurate information. Factuality measures whether claims made by the AI system are grounded in reliable evidence and correctly represent the underlying sources.
This dimension evaluates whether statements accurately reflect the findings of cited studies and whether the AI system avoids introducing unsupported claims. Even the most elegant argument becomes meaningless if the underlying facts are incorrect.
For AI systems used in biomedical research, factual accuracy is therefore the foundation on which every other dimension depends.
2. Depth of Analysis
Scientific reports do not simply repeat facts from individual papers. They synthesize evidence across studies to reveal broader insights.
Depth of analysis measures whether an AI system moves beyond surface level summarization to analyze the relationships between findings. This includes identifying patterns across studies, comparing experimental results and interpreting biological mechanisms that may explain observed outcomes.
A system that demonstrates analytical depth helps researchers understand not just what individual studies say but what the collective evidence suggests.
3. Argument Structure
Scientific conclusions must follow a clear logical structure. Evidence should support claims and reasoning should connect observations to conclusions in a transparent way.
Argument structure evaluates whether an AI-generated report presents a coherent line of reasoning. The report should guide the reader from evidence to interpretation and finally to a well-supported conclusion.
When argument structure is weak, the answer may still appear fluent, but the reasoning chain breaks down. Strong argumentation ensures that conclusions follow logically from the evidence presented.
4. Assumption Transparency
All scientific reasoning involves assumptions. Researchers may assume certain experimental conditions are comparable across studies or that specific biological mechanisms operate in a particular way.
Assumption transparency measures whether an AI system makes these assumptions explicit. Transparent reasoning allows readers to understand how conclusions were reached and where uncertainty may exist.
This dimension is critical for scientific trust. When assumptions are hidden, the answers may appear confident while masking important uncertainties.
5. Limitation Disclosure
No scientific analysis is complete without acknowledging its limitations. Data may be incomplete. Studies may have methodological weaknesses. Evidence may be inconsistent.
Limitation disclosure evaluates whether an AI system recognizes these boundaries and communicates them clearly. This includes identifying gaps in the available evidence and highlighting areas where further research is required.
A report that openly discusses limitations is often more trustworthy than one that presents conclusions without acknowledging uncertainty.
Why Multidimensional Evaluation Matters
These five dimensions are interconnected. A report that is analytically deep but factually incorrect cannot be trusted. A report that is factually accurate but poorly structured may obscure important conclusions. An argument that ignores its assumptions or limitations may appear convincing while leading researchers toward misleading interpretations.
Scientific results are therefore inherently multidimensional. Evaluating AI systems for scientific research must reflect this complexity.
The 5-D benchmarking framework was designed to capture that reality.
Instead of compressing AI performance into a single number, the framework evaluates the criteria scientists use when reviewing research. The goal is to move evaluation closer to the standards used in scientific peer review.
Instead of asking whether an AI system retrieved the correct sentence, we should ask a more meaningful question. Can this system produce a scientific argument that a researcher would respect?
If you are deploying AI systems for scientific research, the benchmark whitepaper provides a practical framework for evaluating their reliability and usefulness. It expands on the ideas and provides a detailed methodology for evaluating AI-generated scientific reports.
Download the full whitepaper to explore the complete 5-Dimensional Benchmarking methodology and evaluation results.
Further reading
.png)

.png)
.png)


.png)

.png)

Get started with Causaly
Ready to transform the way your R&D teams discover and deliver? Take the first step - see Causaly for yourself.
Request a demo