A CIO’s Guide to Agent Orchestration Platforms and Scientific Evidence Systems in R&D
Designing an AI stack where horizontal agent orchestration and vertical scientific evidence systems work together to support high-stakes decisions in biopharma R&D.

Across Pharma and Life Sciences, organizations are converging on a single horizontal agent-orchestration platform and building new AI agents on top of it. In most cases, that platform is Amazon Bedrock, Azure AI Foundry, or Google’s Agentspace.
This consolidation is a good thing. Having one orchestration layer for models, tools, agents, security, and governance makes the data and systems manageable. The same platform can host HR copilots, IT support assistants, finance and productivity agents, and other use cases.
In R&D, however, there is a second question that sits alongside the platform decision: how will organizations handle scientific evidence? Scientific questions call for agents that operate very differently from typical enterprise copilots. They work over literature, pipelines, omics, and internal R&D data, and they need more than generic retrieval connectors and a prompt.
The two systems complement each other. Agent orchestration platforms provide a fabric for building and governing agents across the enterprise. At the same time, scientific evidence systems are vertical applications. They focus on retrieval and reasoning over biomedical information with their own internal coordination to deliver that capability. Both can and should coexist in the same architecture, but they live at different layers.
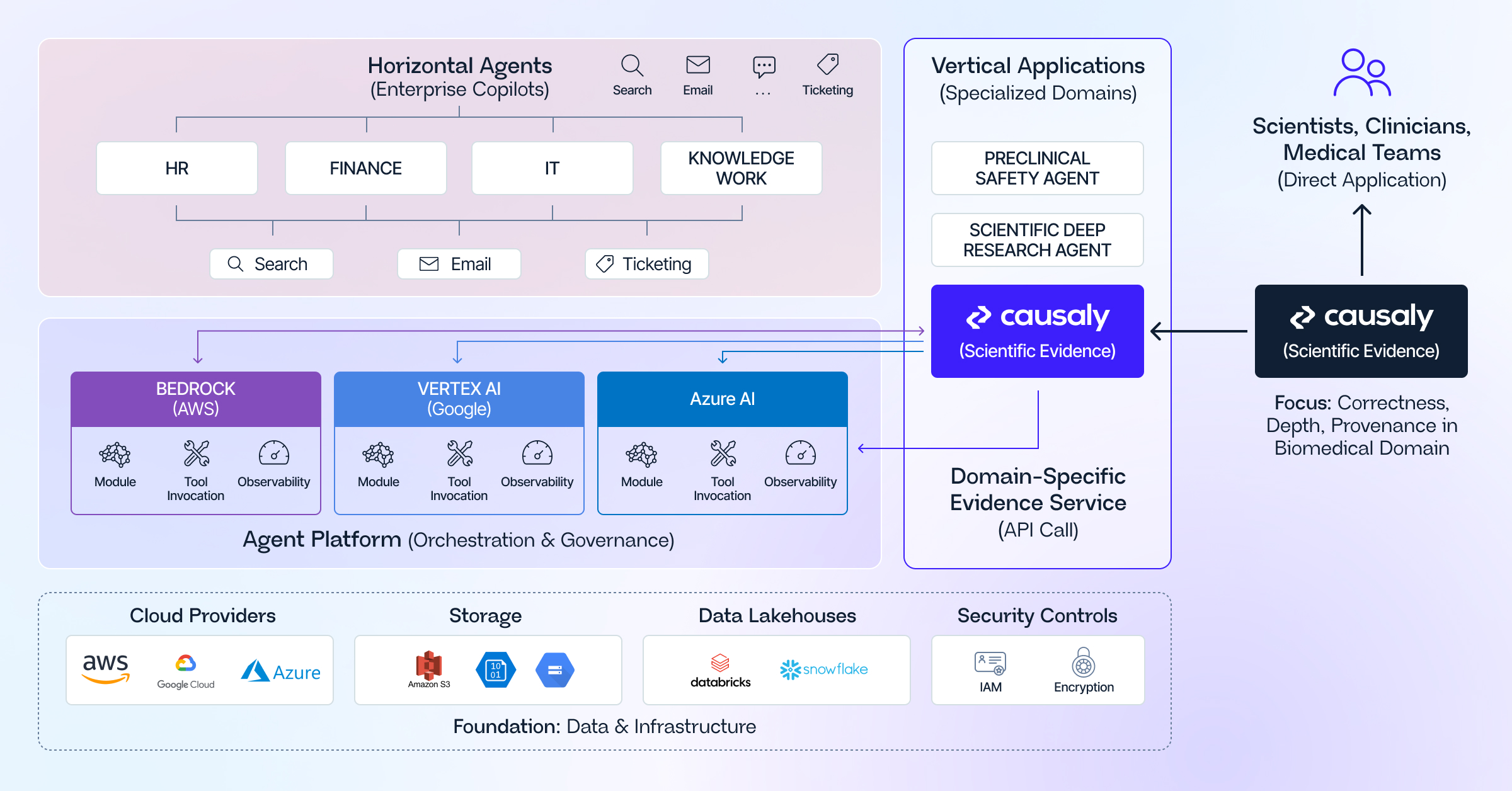
As shown in the diagram above, there is a horizontal bar representing your chosen orchestration platform. With a set of productivity agents running on top, and beside it a vertical block of scientific agents built on a specialized evidence system. The two connect, but they do not replace one another.
What Agent-Orchestration Platforms Deliver
Amazon, Google, and Microsoft orchestration platforms all play a similar role. They provide:
- Managed access to foundation models and endpoints.
- Frameworks for defining agents and multi-step workflows, including planning, calling tools, and maintaining state.
- Built-in capabilities for security, identity integration, monitoring, logging, and cost management.
These platforms are intentionally horizontal. They are built to support a broad range of agents. From HR copilots that answer policy questions and finance assistants that analyze spend, to sales or CRM copilots, IT support bots, and generic “workplace assistants” that help employees navigate documents and applications. The platform provides patterns, guardrails, and shared operational tooling while domain logic lives elsewhere.
From the perspective of R&D IT, this is the right place to:
- standardize how agents run, including which models are approved
- how tools are authenticated
- how interactions are logged and evaluated
- how agents move from prototype to production
What a Scientific Evidence System Adds to the Stack
Scientific questions in discovery, biology, translational research, and clinical development operate differently from typical enterprise questions. A system that helps a biologist assess a target, understand a mechanism, or evaluate a safety signal has to address three tightly linked aspects:
- retrieval
- reasoning
- internal workflow coordination.
Retrieval as a dedicated capability
Scientific evidence is distributed across full-text papers, supplementary materials, patents, conference abstracts, trial registries, pipelines, internal reports, and growing volumes of omics and real-world data.
Important details often live in a specific figure, a table row, or a methodological note rather than in an abstract or title. Entity naming for targets, diseases, phenotypes, and pathways is inconsistent across time and sources.
A scientific evidence system therefore invests heavily in:
- Domain-specific indexing and normalization for biological entities and relationships.
- A biomedical knowledge graph that encodes mechanisms, pathways, and connections and helps resolve synonyms and overlapping terminology.
- Page- and passage-level ranking tuned to scientific questions rather than general enterprise search.
Reaching this level of capability requires a dedicated data and product layer built specifically for scientific content. This should have its own curation, evaluation, and evolution as the science moves. Relying solely on the configuration of a generic vector index exposed through an orchestration platform does not typically achieve the precision and recall levels that R&D teams need.
Reasoning grounded in study context
Scientific reasoning depends strongly on context: model system, species, dose, duration, endpoints, inclusion and exclusion criteria, and prior knowledge about the biology. Two studies that look contradictory at first glance can become consistent once these conditions are taken into account.
A scientific evidence system needs internal representations of studies, cohorts, interventions, and outcomes. It should be able to line up evidence across studies, highlight where results converge or diverge, and anchor conclusions explicitly in that structure. Summarization is part of the workflow, but the core value comes from structured comparison and interpretation rather than narrative alone.
Internal coordination inside the evidence system
To deliver this combined retrieval and reasoning capability, a system like Causaly coordinates several internal components. A typical scientific research run may:
- Query a scientific data fabric that combines curated external content with connected internal sources.
- Use the Causaly Bio Graph to expand and constrain hypotheses and prioritize entities.
- Apply specialized services that stitch together retrieved passages and perform domain-aware reasoning.
- Use additional agent-like components to generate reports and visualizations with page-anchored provenance.
Internally, this involves orchestration of tools and agents, but this orchestration stays entirely within a single vertical application that has a coherent data model and a clearly defined purpose. From the standpoint of enterprise architecture, it operates like any other complex domain system, similar to the way a modern database or analytics engine coordinates internal stages to answer a query.
A layered view of orchestration and evidence
A layered model helps clarify how agent orchestration platforms and scientific evidence systems work together in one stack:
- Data and infrastructure layer – Cloud, storage, data lakes, identity, and security.
- Agent orchestration layer – Amazon, Azure, or Google platforms provide standardized access to models, tools, policies, and observability
- Horizontal agent layer – Finance, HR, IT, and productivity copilots, as well as generic enterprise assistants, running on the chosen orchestration platform and interacting with line-of-business systems.
- Vertical evidence and domain systems layer – Specialized applications that encode deep structure and higher-stakes logic such as regulatory platforms, safety systems, and scientific evidence systems for R&D.
In this setup, a scientific evidence system connects to the stack in two main ways:
- Direct use by scientific teams – Scientists, clinical researchers, and medical teams use it as their primary environment for complex research tasks, mechanism exploration, and evidence synthesis, with full visibility into underlying documents and pages.
- Indirect use through horizontal agents – Agents running on Bedrock, Azure, or Google call the evidence system whenever they receive a scientific question that demands high-quality retrieval and reasoning over biomedical content, rather than relying on generic document search.
The horizontal platform remains the unifying fabric for identity, policies, logging, and lifecycle management. The scientific evidence system becomes one of the specialized capabilities that fabric can invoke whenever a question involves biology, disease, or drugs.
Practical implications for R&D IT architecture
Framed this way, the architectural decisions become clearer:
- First, standardize on one agent orchestration platform as the default environment for building, running, and governing agents across the enterprise.
- Second, define scientific evidence as a distinct capability with its own system that will be responsible for scientific corpora and knowledge graphs, high-quality retrieval at page level, and transparent, context-aware reasoning.
- Third, treat the internal agentic coordination within the evidence system as an implementation detail of a vertical application, not as a competing orchestration layer.
- Finally, expose the evidence system as a first-class tool inside the orchestration platform, so that horizontal agents can hand off scientific questions to a system that is built for that purpose.
The result is an AI stack where finance, HR, and IT copilots operate on a unified orchestration fabric, while scientific agents run on top of a dedicated evidence system that integrates into that fabric. This gives the organization the benefits of platform consolidation along with the depth and reliability required for scientific decisions that depend on complex, evolving evidence.
Further reading






.png)
.png)

Get started with Causaly
Ready to transform the way your R&D teams discover and deliver? Take the first step - see Causaly for yourself.
Request a demo