Building vs. Buying Agentic AI: What Pharma Enterprises Need to Know
A roadmap for balancing innovation speed, cost, and scientific credibility in the age of agentic AI.
.png)
I hear the same themes in every R&D IT/CIO discussion. “We can build this with Copilot, SharePoint, and a vector database.” Or, “We’ll deploy our own RAG stack and plug in ChatGPT or Claude.” Sure, you can spin up a demo in a few weeks and quickly hit 60% in output quality, but the challenge is not 60%. In science, the bar is 80–90% with page-anchored provenance. The last 20–30% is where the real cost lies, and it’s what ultimately determines whether scientists adopt the system or ignore it.
This standard exists because R&D runs on prior knowledge spread across full-text PDFs, methods sections, figures, toxicology tables, ELNs, and internal reports. If a system cannot reliably retrieve the right passages, ground reasoning in structured priors, and trace each claim to sources, it will not withstand nor pass scientific review.
One must also consider the total cost of ownership (TCO), which falls into three stages: building the core, running and evolving in production, and managing the hidden risks that subtly erode ROI when adoption lags.
.png)
What does “build” actually mean
Building is not simply wiring a connector and calling it done. You are creating a scientific information retrieval (IR) system that behaves like a research engine, not a copilot.
A small team can get a prototype off the ground, but achieving 80–90% quality with provenance requires IR and ML engineers, ontologists, platform and evaluation leads, and content operations. You will also need licensed full-text sources, curate gold standards with subject matter experts (SMEs), and manage controlled releases. And as agentic frameworks and models evolve, baselines must be recalibrated, and new data types will demand continuous extensions across parsing, indexing, and quality assurance.
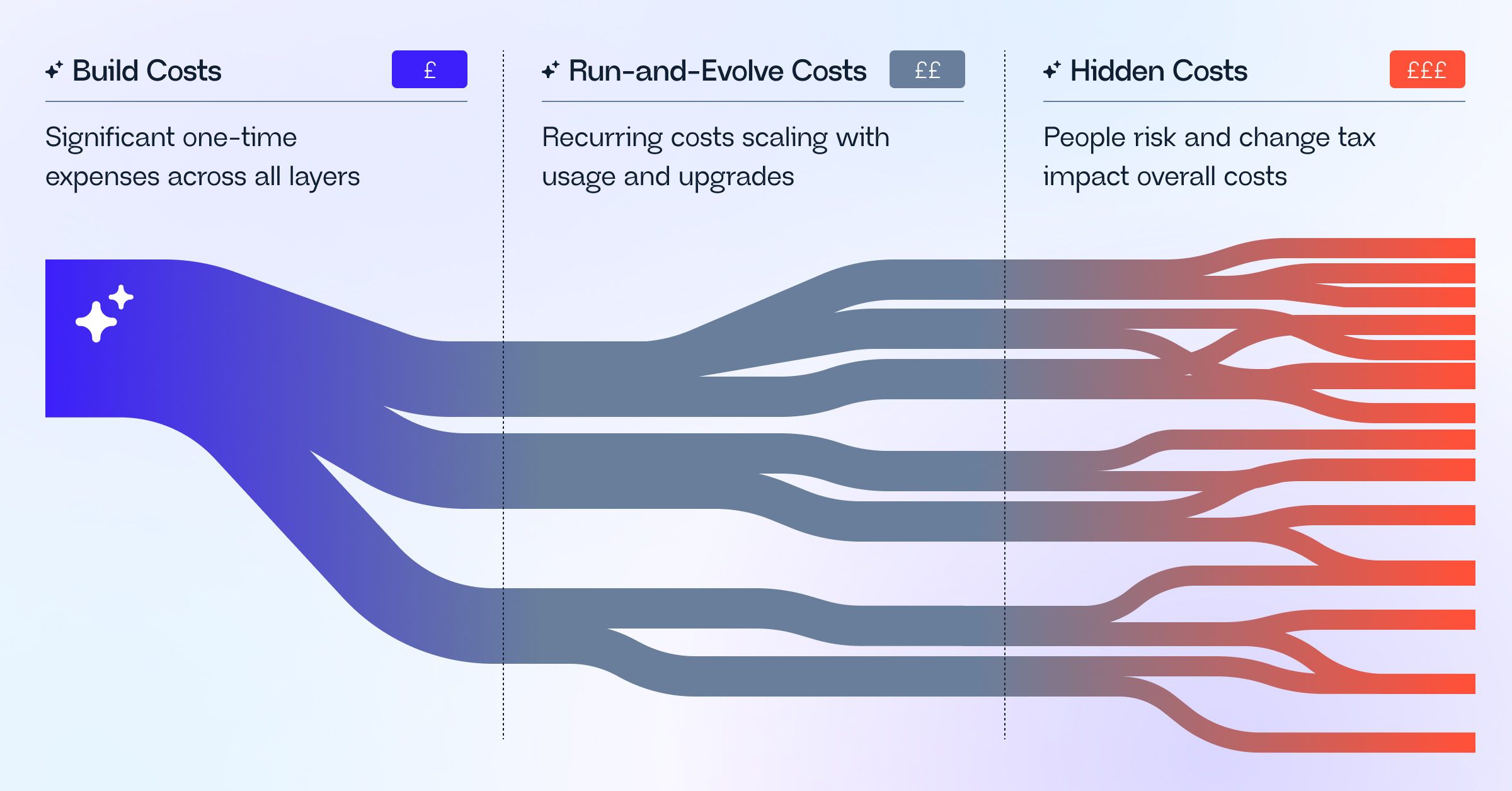
Achieving that level of rigor comes with a layered cost structure that entails:
- Building costs (One-time but significant)
The “build” stage is a one-time cost, but it’s a large one, spanning every layer of the scientific retrieval stack:- Parsing + normalization: Accurately reading PDFs, extracting tables and figures, removing duplicates, and maintaining version history.
- Indexing + retrieval: Combining dense and sparse retrieval with ontology-based filters, re-rankers, query classification, and domain-specific routing.
- Knowledge assets: Linking entities, mapping ontologies, building knowledge graphs, and resolving data conflicts.
- Agentic layer: Planning, tool coordination, guardrails, activity logging, replay/reproducibility.
- Evaluation harness: Creating gold-standard datasets, scientist review workflows, maintaining regression gates for every pipeline and model update.
- Security/compliance: Enforcing policies, redacting sensitive data, maintaining audit trails, vendor assessments
- Running-and-evolving costs (Recurring)
Once the foundation is built, the work shifts from creation to evolution. These costs are recurrent, scaling with usage, and compounding with every upgrade cycle as systems, models, and data continuously change.- Content operations: Daily ingestion, rights management, corpus maintenance, and failure rectification.
- Graph upkeep: Managing merges, temporal validity, and integration of new modalities. Recomputing features and re-validating retrieval pipelines
- Ontologies and vocabularies: Maintaining MeSH, UMLS, HGNC, proprietary taxonomies, and drug/chemical lists, all of which require continuous updates without breaking anchors or links.
- IR quality: Retuning chunking, windowing, and re-rankers as document formats, journal structure, and query mix change.
- Models and Evaluations: Adapting to new model families, longer contexts, and new tool APIs. Re-baselining evaluations, migrating prompts/plans, retraining selectors.
- Compute + storage: Managing ingestion workloads, vector/symbolic indices, GPUs for re-ranking and extended runs, hot/warm/cold storage tiers.
- Model usage: LLM/API calls for chat, planning, and Deep Research tasks.
- Governance drift & Security: Adapting to policy changes, new geographic rules, retention updates; maintaining certifications and audit readiness.
- Content operations: Daily ingestion, rights management, corpus maintenance, and failure rectification.
- Hidden costs and risks
Even with detailed planning, certain costs and risks remain largely invisible until they surface:- People risk: Specialized skills are scarce, and turnover resets calibration, making you lose time, context, and momentum
- Change tax: Every upstream modification (whether to a model, ontology, or connector) forces a re-testing and re- validation across pipelines.
Buy vs. Build: How to decide?

A pragmatic strategy is buy-core, build-edge. Buy a research-grade foundation that already delivers full-text coverage, hybrid IR, graph grounding, governed agents, and auditability. Build the edges that make it yours. Bring your investigator brochures, tox reports, ELNs, and study reports into a Private Data Fabric. Add your proprietary ontologies or code lists. Add task-specific agents for your internal workflows. Keep ownership of data, identity, and policy. And spend engineering time where it creates scientific advantage, and not on re-implementing IR infrastructure.
What Causaly Agentic Research provides
This is exactly why we built Causaly Agentic Research. Causaly indexes full-text science with page-level anchors. It fuses public, licensed, and private corpora into one governed index. It reasons over Bio Graph and Pipeline Graph, so answers are constrained by known biology and development context. Deep Research runs multi-step plans and leaves an evidence matrix, assumptions table, and a provenance log. It is deployable in your environment with clear governance. Enabling your team to focus on what is proprietary: your data, your questions, your workflow, your decisions.
Beyond buy vs. build: Transformation vs. tooling
Agentic tools are multi-purpose. They can plan, retrieve, and reason across many domains. But that flexibility is not self-explanatory within R&D because a scientist does not “use a chatbot.” They run a workflow that is focused on preclinical safety, target assessment, assay development, mechanistic biology. Each of these has defined inputs, review gates, and evidence standards.
However, GenAI is not a replacement for these workflows; it is a capability that must be integrated to your workflow. When done properly, prompts become procedures. Retrieval becomes an evidence step. Outputs become artifacts that can withstand scrutiny. Without this integration, the same agent that is capable of doing many things ends up doing nothing within your process.
Adoption is an evolving program, not a feature
This is where buy-versus-build becomes practical. Even if an IT team funds the full TCO and meets scientific standards, adoption still depends on a broader transformation program. Scientists need to understand how the tool align with their SOPs, what qualifies as “good evidence”, and when to escalate. Train-the-trainer networks, workflow-specific templates, and provenance literacy often make the difference between short-term pilot enthusiasm and sustainable, organizational-wide use.
A convincing demo or a working file connector does not make a research system. In R&D, usefulness and functionality only exists at the intersection of capability and governance.
Causaly Agentic Research operates at that intersection, combining full-text retrieval with page anchors, graph-grounded reasoning, governed agents, and outputs that can withstand scientific review. The same technology that looks generic in a demo becomes adoptable only when integrated to your workflows and run as part of a structured change program.
In the end, buy versus build is not a technical choice, it’s a strategic one. The end goal is scientific adoption, not internal craftsmanship. The faster you move from prototypes to trusted systems that scientists can use with confidence, the faster the return on both innovation and investment.
Further reading

.png)

.png)
.png)


.png)

Get started with Causaly
Ready to transform the way your R&D teams discover and deliver? Take the first step - see Causaly for yourself.
Request a demo