Garbage In, Hallucinations Out: How to Stop AI Hallucinations in Scientific R&D
If you want a trustworthy scientific AI, start where the source of truth enters the system, that is the retrieval.
.png)
Most AI evaluations in science start at the end. People focus on the final output, judging the report, the summary, and the hypothesis. They debate the reasoning model, asking “which LLM do you use?” and whether the model was fine-tuned or trained. While these are important questions, the first step is usually overlooked: which is information retrieval (IR), also known as Search. If the system cannot find the right evidence, the best model will still invent bridges to connect gaps. You see these same issues every week: uncited claims, incorrect claims, fake references, and a wild variance in what sources were considered. That is a retrieval problem, not a model problem. One study reveals that between 50% and 90% of LLM responses are not fully supported, and sometimes contradicted, by the sources they cite.
The issues most teams encounter are:
- Statements without citations, even when correct.
- Statements that are wrong and uncited.
- References that do not exist or do not support the claim.
- Coverage uncertainty: did the system look at 10% of the evidence or 90%?
The more irrelevant documents get into the model’s context window, the higher the likelihood that the model will hallucinate, make up references, or try to fill in the missing information by itself.
Why do AI models hallucinate?
The root cause is that they rely on general search, not scientific retrieval. Generic AI (ChatGPT, Claude, Gemini) can search the web and connect to file stores. That is a general search. It finds documents. It does not consistently find evidence. Scientific research depends on methods sections, tables, figures, and internal reports. The proof can be hidden in a full text or private data, buried on page 7 in a subsection of a document. Without a scientific retrieval process, the system pulls the wrong chunks or misses the important pages. The LLM then fills the gaps with confident language and gives an output. In other words, garbage in, hallucinations out.
Why scientific IR is hard
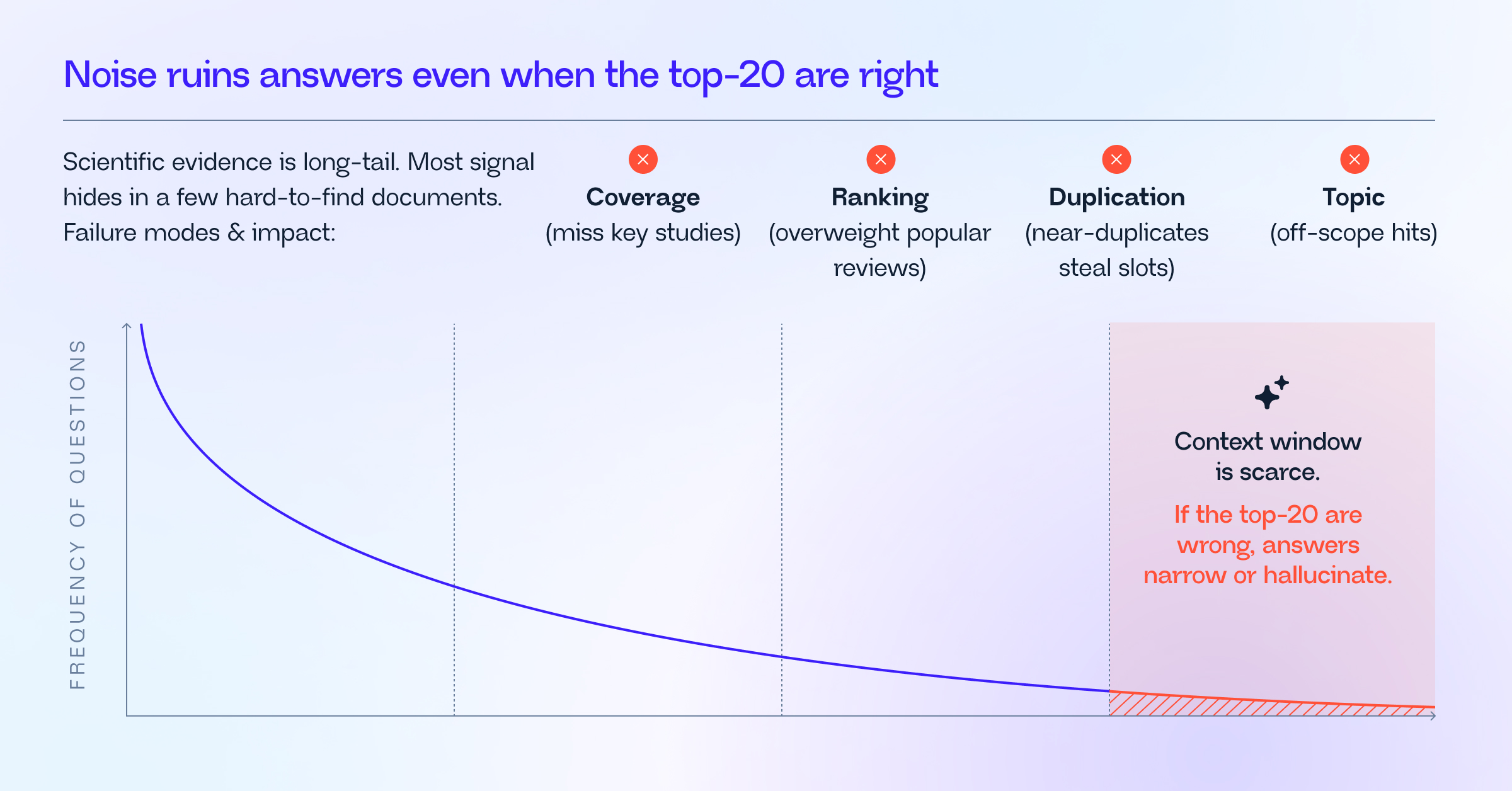
Scientific evidence follows a long-tail distribution pattern. A few hard-to-find pages carry most of the decision-making signal. If those pages don’t make it into the model’s top-K context window, the model will either answer narrowly or hallucinate to fill the gaps. Context is scarce, so every wrong, duplicated, or off-topic chunk limits access to the few pages that matter.
What “scientific search” actually means
Scientific information retrieval is not a “vector search on PDFs.” It is a governed pipeline that:
- Covers the right corpus in a controlled Data Fabric: Includes full-text literature, patents, clinical reports, and your private PDFs. Not just abstracts and links
- Understands domain structure: Uses biomedical ontologies and knowledge graphs for entity normalization, synonym control, and relationship context.
- Ranks at page and chunk level: Treats every page, figure, or table as the unit of truth, with each one chunked, retrieved, and scored. Retrieval must operate at this level of granularity.
- Reduces noise before reasoning: Applies hybrid ranking (symbolic + semantic + ontology/graph signals) to deliver the best top-K pages to the model, not the most obvious ones.
- Produces audit artifacts: Generates page-anchored citations, an evidence matrix, and a provenance log so reviewers can trace every claim.
If any of these links are missing, reasoning quality degrades.
The four failure modes of generic AI systems
- Coverage miss: The system never surfaces key studies or the decision-making methods, tables, or pages.
- Ranking bias: Popular reviews and broad summaries crowd out high-signal primary pages that contain the real evidence.
- Duplication: Near-identical chunks from the same review, preprint, or internal report consume context budget without adding new evidence.
- Off-topic documents: Semantically related but clinically irrelevant documents enter the context window, amplifying ambiguity and spurring over generation of evidence.
Each failure directly increases hallucination pressure: thus, missing signal → the LLM interpolates.
How to eliminate AI hallucinations from scientific workflows
The solution is a retrieval-first workflow that treats scientific search as the primary task and reasoning as the next step. The best way to do this is to start by planning targeted queries, then search full text and private documents together across all relevant sources. Normalize terminology with domain knowledge, select pages that actually contain the signal, remove duplicates, and filter off-topic results. Only then should the model receive the best, page-anchored evidence.
The outcome is a compact, diverse, high-signal context window that reduces hallucination pressure and makes every downstream step, reasoning, critique, and orchestration more reliable.
This is exactly how Causaly Agentic Research works. It unifies literature and your internal PDFs in a governed data fabric, uses biomedical knowledge to keep retrieval on-topic, and ranks at the page, table, and figure level so the top-K results contain what reviewers care about. Outputs are cited by default and ship with an evidence matrix and provenance, so teams can trace every claim.
Conclusion
If you want trustworthy scientific AI, start where the source of truth enters the system: retrieval. While generic chats optimize conversation, Causaly optimizes evidence, then allows the model to reason over it.
Further reading

.png)

.png)
.png)


.png)

Get started with Causaly
Ready to transform the way your R&D teams discover and deliver? Take the first step - see Causaly for yourself.
Request a demo